Last Updated on: 25th July 2025, 07:35 pm
Overview
At RTB House, our data center network is built on a simple, reliable principle:
No VXLAN. No EVPN. No overlays. Just plain Layer 3.*
(*Wherever possible, we avoid overlays and L2 dependencies. In a few edge cases, we may use encapsulation where it makes sense.)
We connect every server directly to the routed fabric using BGP Unnumbered over VLAN-tagged subinterfaces. There are no IP addresses on physical links, only stable loopbacks and dynamic BGP peering via IPv6 link-local addresses.
This minimalist design eliminates unnecessary complexity while ensuring high redundancy:
- Each server is at least dual-homed to top-of-rack switches.
- BGP sessions run on all available interfaces, enabling ECMP, fast failover, and horizontal scalability of server connectivity.
- No L2 loops, no spanning tree, no tunneling overhead.
The result is a resilient and scalable Layer 3 architecture, purpose-built for automation and availability at scale.
Example: Server interface setup
At RTB House, we standardize the network configuration across all servers to ensure consistency, automation readiness, and minimal manual intervention. Each server is connected to the network fabric using multiple VLAN-tagged interfaces and a loopback for BGP identity, all without assigning any IP addresses to physical links.
This example is based on a high-performance compute server equipped with Two Mellanox (NVIDIA) ConnectX-7 MCX755106AS-HEAT network cards. Each card provides dual-port QSFP112 interfaces (each 200 Gbps capable), for a total of four high-speed uplinks.
Here’s the corresponding snippet from /etc/network/interfaces:
# Primary interface
allow-hotplug eth0
iface eth0 inet manual
allow-hotplug eth0.205
iface eth0.205 inet manual
# Ensure stable IPv6 link-local addressing
up echo 0 > /proc/sys/net/ipv6/conf/$IFACE/disable_ipv6
up echo 0 > /proc/sys/net/ipv6/conf/$IFACE/use_tempaddr
# Secondary uplink
allow-hotplug eth1
iface eth1 inet manual
allow-hotplug eth1.205
iface eth1.205 inet manual
up echo 0 > /proc/sys/net/ipv6/conf/$IFACE/disable_ipv6
up echo 0 > /proc/sys/net/ipv6/conf/$IFACE/use_tempaddr
# Placeholder for additional interfaces (up to eth7)
allow-hotplug eth2
iface eth2 inet manual
allow-hotplug eth2.205
iface eth2.205 inet manual
up echo 0 > /proc/sys/net/ipv6/conf/$IFACE/disable_ipv6
up echo 0 > /proc/sys/net/ipv6/conf/$IFACE/use_tempaddr
# ...
# Configuration repeated up to eth7, even on servers with fewer NICs
# This simplifies automation and ensures consistent provisioningAnd the loopback interface used for BGP routing identity:
auto lo:101
iface lo:101 inet static
address 10.167.142.210
netmask 255.255.255.255Key characteristics
- The server uses four physical ports across two dual-port NICs, all connected to the network fabric via VLAN 205.
- Each VLAN-tagged (sub)interface (ethX.205) is used for MP-BGP peering over IPv6 link-local addresses with no IP assigned to the physical link(aka BGP Unnumbered).
- The loopback alias (lo:101) holds the only configured IP and serves as the BGP router ID and next-hop source (there can be multiple loopback aliases in Linux).
- The interface configuration includes eth0 through eth7 regardless of how many NICs are installed. This standardization simplifies image-based provisioning, automation, and failover readiness.
Example: BGP configuration and routing in practice
Once a server is physically connected via VLAN-tagged subinterfaces (e.g., eth0.205 to eth3.205), RTB House uses FRRouting (FRR) to establish BGP Unnumbered sessions with the top-of-rack (ToR) switches over IPv6 link-local addresses. This setup enables dynamic routing, redundancy, and load balancing—without assigning IP addresses to the physical interfaces.
Below is a real configuration from a production server:
!
frr version 9.1.2
frr defaults datacenter
hostname cache210.sin.creativecdn.net
no ip forwarding
no ipv6 forwarding
service integrated-vtysh-config
!
router bgp 4220213120
bgp router-id 10.167.142.210
no bgp hard-administrative-reset
no bgp graceful-restart notification
bgp bestpath as-path multipath-relax
bgp bestpath compare-routerid
neighbor LESW peer-group
neighbor LESW remote-as external
neighbor LESW description To sonic router
neighbor LESW capability extended-nexthop
neighbor eth0.205 interface peer-group LESW
neighbor eth1.205 interface peer-group LESW
neighbor eth2.205 interface peer-group LESW
neighbor eth3.205 interface peer-group LESW
neighbor eth4.205 interface peer-group LESW
neighbor eth5.205 interface peer-group LESW
neighbor eth6.205 interface peer-group LESW
neighbor eth7.205 interface peer-group LESW
!
address-family ipv4 unicast
redistribute connected route-map EXPORTLO
neighbor LESW soft-reconfiguration inbound
maximum-paths 64
exit-address-family
exit
!
ip prefix-list from-lo-accepted seq 100 permit 0.0.0.0/0 ge 32
ip prefix-list from-lo-accepted seq 500 deny any
!
route-map EXPORTLO permit 1
match interface lo
match ip address prefix-list from-lo-accepted
exit
!
route-map EXPORTLO deny 100
exit
!
ip nht resolve-via-default
!
ipv6 nht resolve-via-default
!
endKey routing policies
- The loopback IP (10.167.142.210) is used as the router ID and next-hop source.
- All .205 VLAN subinterfaces are attached to the LESW peer-group, which handles dynamic BGP sessions.
- The maximum-paths 64 directive enables ECMP across multiple uplinks.
- Route-map ensures that only loopback-sourced prefixes (e.g., service IPs) are advertised.
Resulting routing table
Once BGP peering is established with the ToR switches over all active interfaces, the server’s routing table reflects the default route learned via BGP, distributed evenly across all uplinks:
# ip r
default nhid 37 proto bgp metric 20
nexthop via inet6 fe80::c2c9:89ff:fe28:9ec2 dev eth3.205 weight 1
nexthop via inet6 fe80::c2c9:89ff:fe28:9ec2 dev eth2.205 weight 1
nexthop via inet6 fe80::c2c9:89ff:fe28:b6c2 dev eth1.205 weight 1
nexthop via inet6 fe80::c2c9:89ff:fe28:b6c2 dev eth0.205 weight 1What this means:
- The default route is provided via BGP, not statically configured.
- Traffic is distributed over all active BGP sessions using ECMP (weight 1 per path).
- Next-hops are IPv6 link-local addresses, as expected in a BGP Unnumbered setup.
- The system is resilient—if any link or neighbor fails, BGP automatically withdraws the path and rebalances the flow.
Operational impact
This combination of automated BGP peering and multi-uplink ECMP routing gives RTB House servers:
- High availability—multiple interfaces ensure link-level redundancy.
- Scalability—easily support more interfaces or service IPs without changing core routing logic.
- Overlay-free simplicity—no tunnels, no encapsulation, just pure Layer 3 routing.
- Fast convergence—BGP allows quick reaction to link or neighbor loss.
- Stability—removing a server does not cause any network disruptions, as MP-BGP ensures seamless route withdrawal
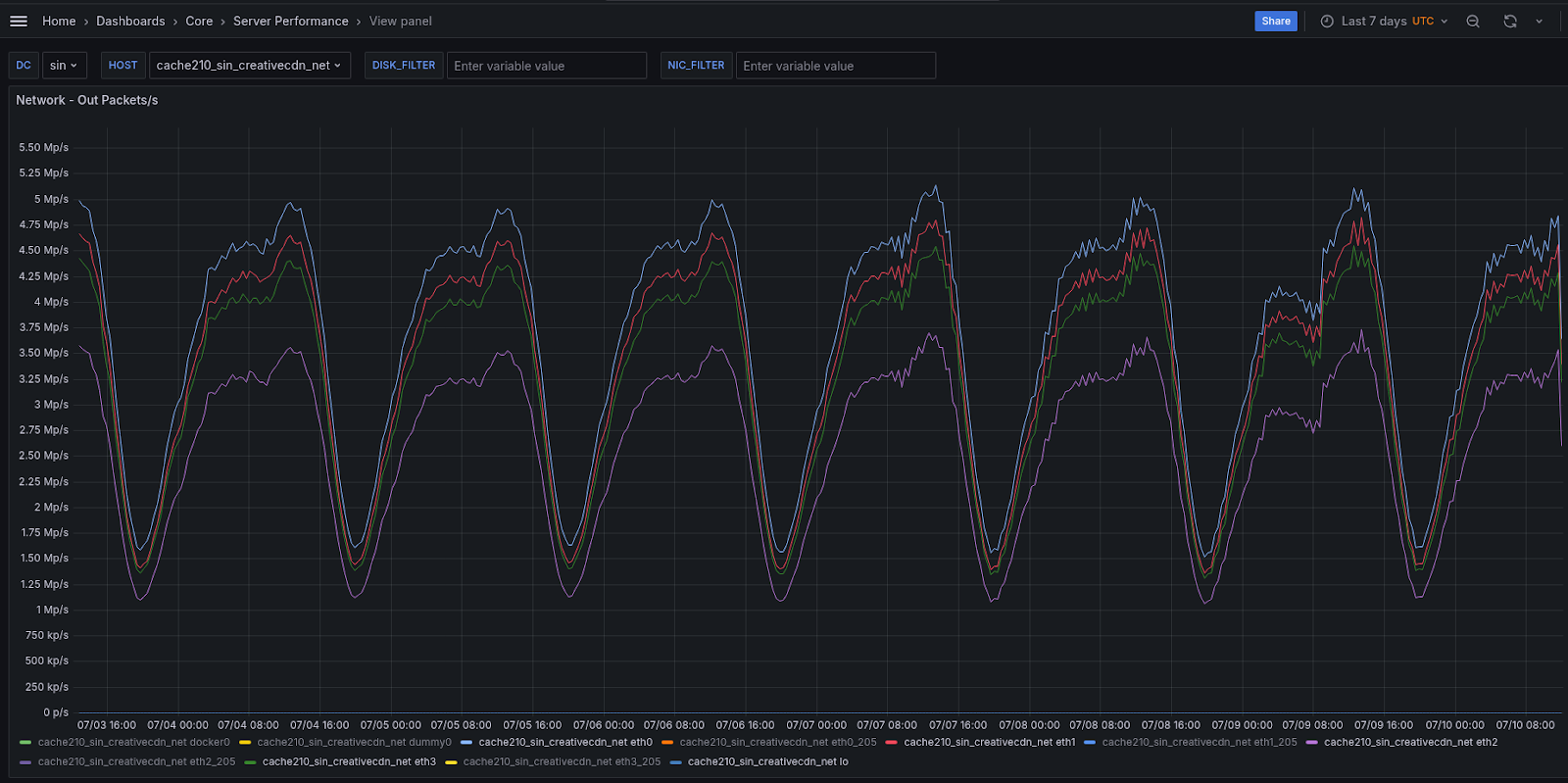
Example: Live traffic distribution (PPS and Mbps stats)
The effectiveness of RTB House’s multi-uplink BGP Unnumbered setup is clearly visible in real-world traffic data. The following graph shows the outgoing packet rate per interface on the server cache210, collected over the last 7 days. Peaks reach above 5.0 M packets per second, demonstrating the high-throughput capabilities of this configuration.
Because RTB House’s infrastructure powers real-time ad delivery systems, low latency and subzero packet loss are non-negotiable. This design ensures that:
- Traffic is balanced across multiple high-speed interfaces.
- There is no congestion or oversubscription on any single link.
- And most critically, there are no observed packet drops under load, keeping response times consistent across billions of ad requests.
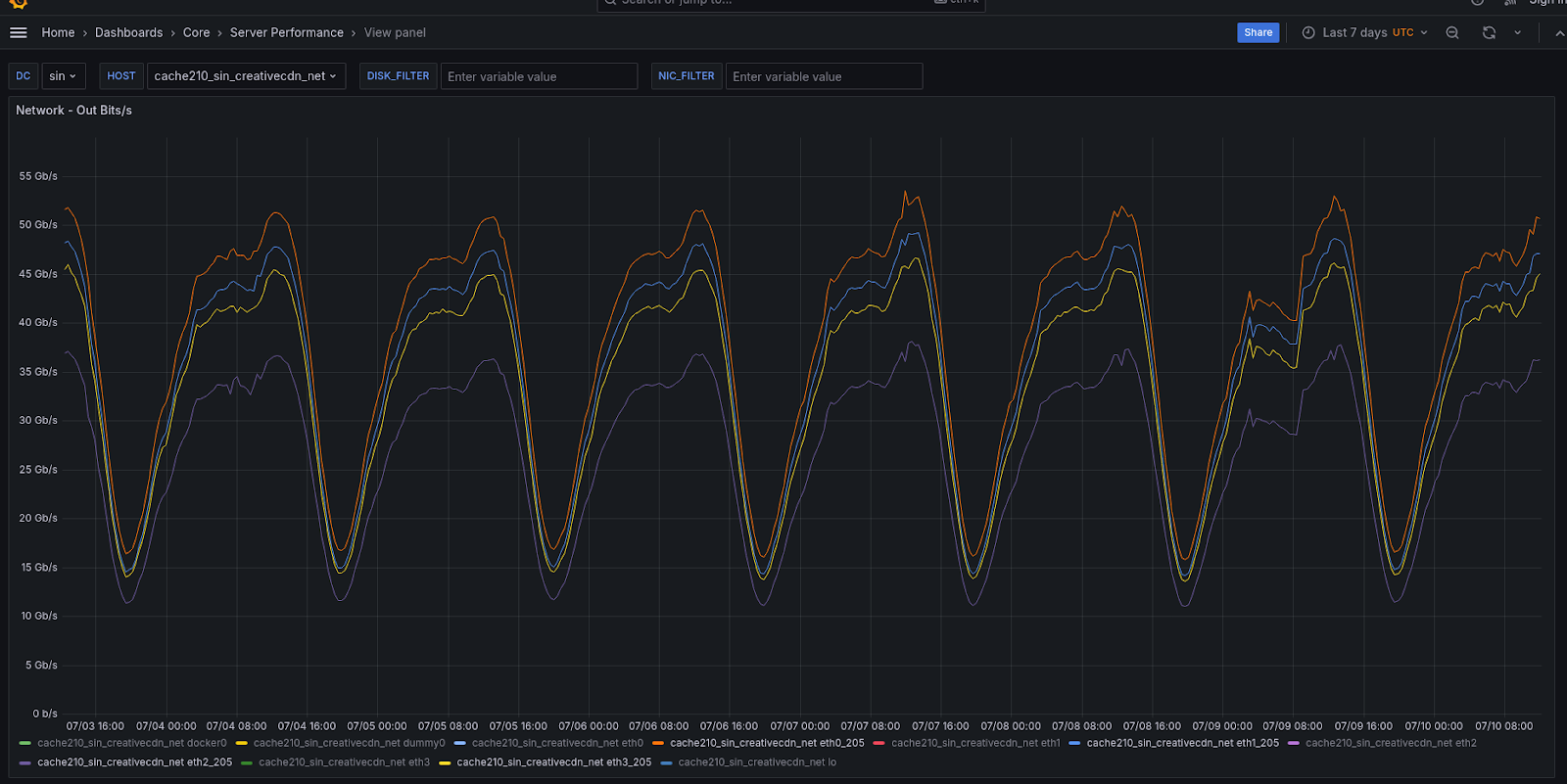
A similar pattern is observed with data throughput:
Summary
RTB House connects servers using a simple, overlay-free Layer 3 network and BGP Unnumbered over VLAN-tagged interfaces, with only loopback IPs set and dynamic BGP peering via IPv6 link-local addresses. This setup is highly resilient, automated, and redundant.
While some may consider this a non-standard method, there are now multiple RFC drafts (including one by Russ White, Jeff Tantsura, and Donatas Abraitis) aimed at making these techniques part of official networking standards. Thanks to the ongoing work of these and other RFC authors, this approach is likely to become widely adopted in the near future!