Last Updated on: 25th March 2025, 03:44 pm
The best decisions are informed ones—and for us, that means having timely, accurate data at our fingertips
In today’s data-driven landscape, having data arrive late or incomplete can undermine crucial business initiatives, from campaign optimization to financial forecasting. The ability to process vast amounts of data quickly, reliably, and at a reasonable price is essential for organizations looking to stay competitive.
At RTB House, we heavily utilize BigQuery to run data pipelines calculating various business metrics that provide insights into campaign performance, budgets, revenue, and beyond—ensuring our teams have timely, accurate information to make data-driven decisions.
Any bottleneck or slowdown in processing isn’t just an inconvenience; it can lead to missed opportunities, inaccuracies, and mounting costs.
In the following sections, we’ll share the story of our migration from on-demand to capacity-based BigQuery pricing, describing how the transition looked for us and the findings we gathered. Nevertheless, there’s more than one way to undertake this transition; every environment poses unique challenges and opportunities, so we encourage you to adapt our findings to your specific context.
BigQuery’s compute pricing models
Before we dive into the specific challenges of on-demand pricing, let’s establish a quick foundation of BigQuery’s two main pricing models.
On-demand (pay per TiB)
With on-demand pricing, you pay based on the number of bytes processed by each query (with the first 1 TiB per month for free). It provides access to up to 2000 concurrent slots (compute resources) shared across the project with some burst capacity.
Capacity-based (pay per slot-hour)
With capacity-based pricing, you are billed based on the compute capacity you utilize, measured in slots (virtual CPUs) over time rather than the amount of data processed. It leverages BigQuery reservations, which can include optional long-term commitments (offered at discounted rates). Within each reservation, you can configure:
- Baseline Slots: A fixed pool of available slots that you consistently pay for.
- Autoscaling Slots: Dynamically allocated slots that ramp up to handle spikes in workload and scale down during idle periods, ensuring you only pay for what you use.
Challenges with on-demand in our environment
At the time, we used a single GCP project for both data-processing jobs and the queries originating from our services (e.g., microservices or user dashboards). As our data volume continued to grow, we began observing three major pain points:
- Slot limit constraints
With multiple heavy queries running concurrently, we often approached or hit the 2,000 on-demand slot cap. This led to timeouts and delays, resulting in late-arriving data.
- Rising costs
An increasing number of pipelines and rapidly expanding data volumes drove up our monthly bills under on-demand pricing.
- Negative impact on users
Because data processing and interactive queries were sharing the same limited resources, user-facing dashboards and services sometimes experienced longer load times whenever heavy jobs were running in parallel.
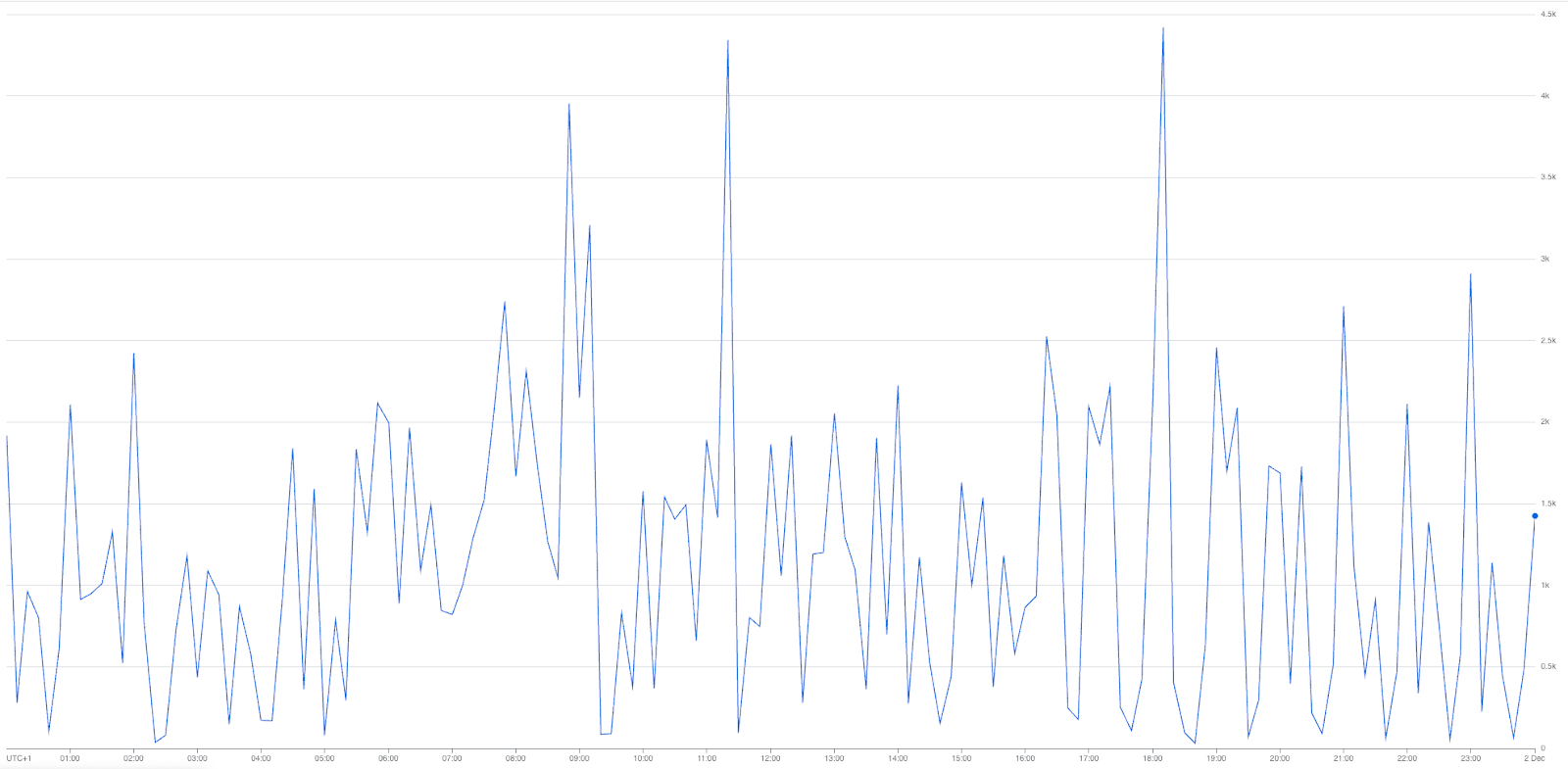
slots/allocated_for_project metric
With a clear picture of how on-demand pricing was holding us back, we decided to explore the potential benefits of capacity-based pricing.
Analysis
Any capacity-based migration should start with a careful evaluation of your data usage patterns. Below is how we approached our own analysis, from pinpointing key workloads to creating a focused migration plan.
Understanding our workload
The key to our analysis was understanding how our workloads behaved—which queries ran, when they ran, and how they consumed BigQuery resources. By examining concurrency peaks, average runtimes, data volumes, and cost trends, we identified two primary workloads:
- Batch data-processing jobs: High-volume transformations, representing roughly 77% of our total slot usage.
- Live queries: Ad hoc or interactive queries run by end users and internal services to view real-time or near-real-time reports.
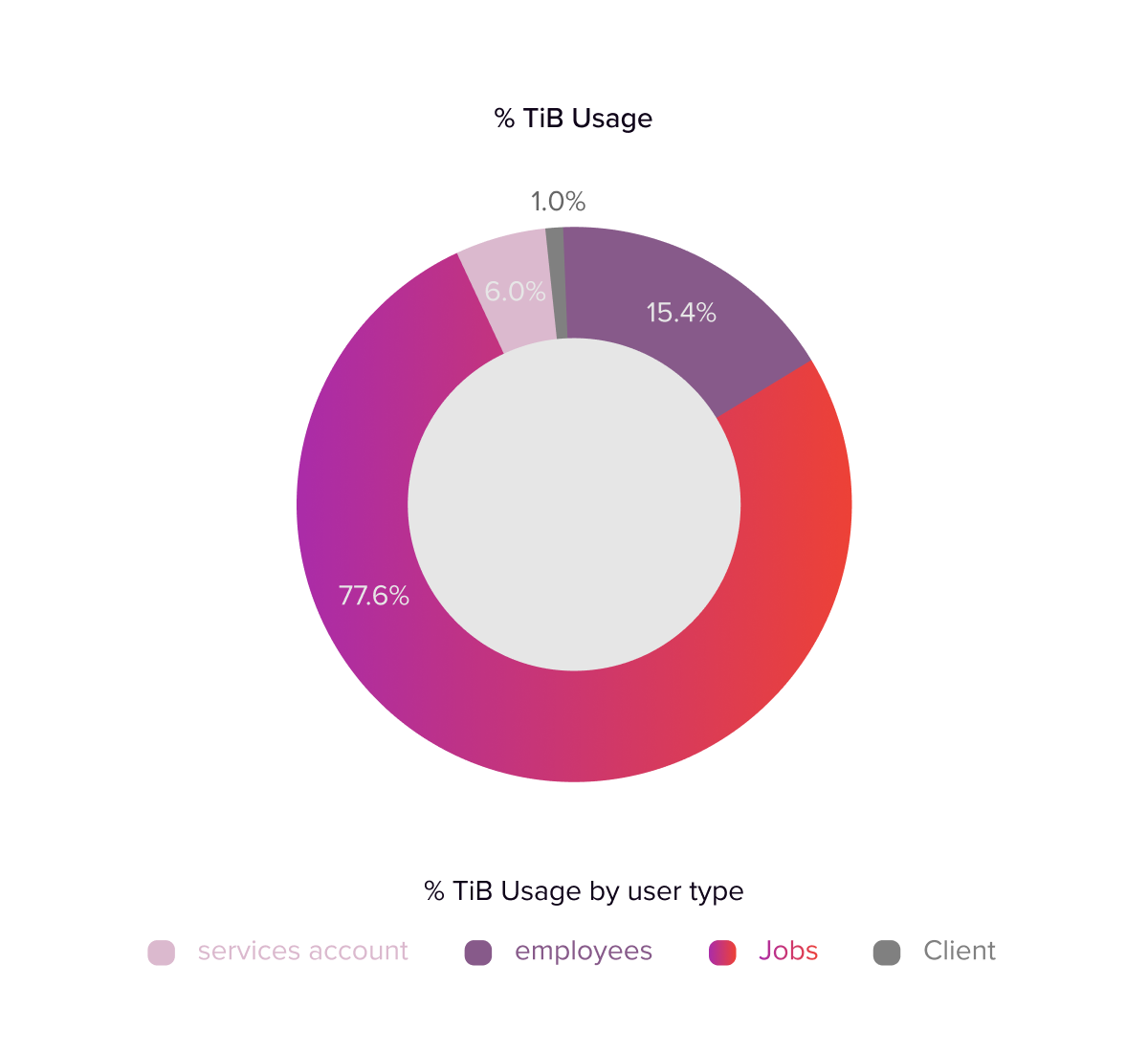
Given that batch jobs drove the majority of our usage and caused the most significant concurrency and cost issues, we decided to consider introducing capacity-based pricing only for these jobs initially. This “one-thing-at-a-time” approach also minimized the risk of affecting end-user queries, making it easier to manage potential issues before expanding the model to other workloads.
Slot analysis and cost modeling
Every workload is different so there is no one-fits-all approach to forecast the reservation configuration. Historical slot usage data is key in estimating realistic values for both baseline and autoscaling parameters.
We collected detailed metrics from BigQuery audit logs and slot monitoring tools to understand how job demands fluctuated, examining:
- Minutely, hourly, daily, and monthly aggregated slot usage.
- Cost variations tied to these usage spikes.
- Spiky vs. steady patterns in batch workloads.
These insights confirmed that batch processing came in bursts, followed by low slot usage periods—what seemed the perfect use case for a mix of baseline and autoscaling slots.
With the usage patterns in hand, we developed multiple ‘what-if’ scenarios to forecast cost and performance under capacity-based pricing, considering different baseline autoscaling settings along with an estimated percentage of autoscaling slot utilization. The modeling suggested that capacity-based pricing could bring us predictable performance while lowering monthly fees.
It is worth mentioning that we briefly experimented with the BigQuery slot estimator during our planning, but it recommended larger baseline and autoscaling values than we felt necessary. This was likely due to the spiky nature of our scheduled jobs, so we opted instead for a more tailored approach based on our internal usage patterns.
Drafting a migration plan
Armed with our findings, we laid out a step-by-step strategy:
1. Set up a separate GCP project for batch jobs.
Isolate these heavy tasks from user-facing queries, simplifying monitoring and resource allocation.
2. Test with dry runs.
Launch representative jobs in this new setup to observe autoscaling behavior and confirm that job runtimes remain acceptable.
3. Full rollout (with safety thresholds).
Migrate all batch jobs and apply reservation parameters from our analysis, slightly overestimating slots to mitigate the risks.
4. Ongoing monitoring and tuning.
Track slot utilization, costs, and job durations daily, refining baseline balance vs. autoscaling as needed.
Addressing our pain points
Such migration provided a direct solution to our three major challenges:
- Preventing 2,000-slot bottlenecks with managed baselines and autoscaling features.
- Reducing costs according to estimations while gaining better predictability.
- Minimizing interference with user queries by separating the jobs workloads into a separate GCP project.
In the following chapters, I will outline the feasibility studies we ran, our step-by-step migration approach, and the outcomes that justified our decision.
Implementation strategy
Our first step was to create a new GCP project specifically for experimenting with capacity-based pricing. We configured the necessary logging and IAM permissions, then established a reservation in this project with a small autoscaling slots pool. Separating the reservation into its own project offered two key advantages:
- Isolation: We could continue running the majority of our pipelines in on-demand mode without the risk of breaking anything during the experiment.
- Visibility: By focusing slot-usage metrics on just a handful of jobs, we gained clearer insights into how the autoscaler behaved under different load scenarios.
Before moving all our data-processing tasks, we ran just one job in this new project. This “pilot” approach allowed us to confirm:
- The reservation was functioning as expected.
- Logs and permissions were set up correctly.
- Our standard queries would run seamlessly under the new pricing model.
Once we saw no issues with that single job, we gradually migrated a few additional jobs into the project, further validating performance and cost under capacity-based pricing.
During these tryouts, we closely monitored slot usage in near-real time, noting:
- Scaling up delay: The autoscaler typically took 5–10 seconds to respond when a new job spiked resource demand.
- Scaling down delay: Reducing slots could sometimes take up to a minute, meaning we briefly paid for more slots than strictly needed after a job finished.
- Overprovisioning: We observed that BigQuery might temporarily allocate more slots than the workload required, possibly to ensure queries weren’t starved of resources.
These observations helped us better understand how BigQuery’s capacity-based autoscaler would behave with our spiky workloads. We decided any slight delay or overprovisioning was acceptable for batch jobs that didn’t require real-time performance.
Having validated the autoscaler’s performance, we moved on to running our entire batch workload under the new reservation. We used the reservation parameters developed from our feasibility analysis, plus a safety threshold to handle unanticipated usage spikes.
Tuning
Once we had fully migrated our batch workloads to capacity-based pricing, we turned our attention to tuning both costs and performance. We knew we needed reliable observability to understand how changes to baseline and autoscaling parameters impacted our jobs. Using Looker Studio and BigQuery connectors, we tracked key metrics such as:
- TiB processed: Total and by job type.
- Slot-hours consumed: Overall usage and by job type.
- Ratio metrics: Such as slot hours per TiB, to understand efficiency.
- Execution times: Average and maximum run times.
- Autoscale utilization: The percentage of autoscale slots used.
- Cost comparison: On-demand vs. capacity-based price comparison.
These dashboards, combined with BigQuery resource utilization monitoring, gave us near real-time insights into our job performance, costs, and reservation utilization.
From the start, a surprising discovery was that we often had periods where no jobs were running, yet baseline slots remained allocated and billed. Because we initially overprovisioned our reservations to avoid timeouts, this resulted in wasted capacity.
In response, we began trimming down our baseline and autoscaling settings to see if we could encourage existing queries to spread more evenly across a smaller pool of slots. The theory was that if queries slowed slightly, they might “fill in” those idle periods, enabling us to justify a baseline commitment.
What we observed was:
- Light jobs still ran quickly, even with fewer slots.
- Heavy jobs grew longer as the total available capacity dropped, sometimes affecting completion times more than we wanted.
After multiple rounds of experimentation, we concluded that for our spiky analytical workloads where a few seconds’ delay for slot scaling posed minimal business risk, relying solely on autoscaling was the most cost-effective approach. By removing baseline slots, we eliminated paying for capacity during idle periods while still maintaining acceptable performance levels for our batch jobs.
Finalizing the production environment
Once we were satisfied with our capacity-based setup and autoscaling configuration, we took steps to make it production-ready. Following Google Cloud’s best-practice guidelines, we created a BigQuery Admin project for centralized administration of reservation resources and billing.
To further refine our approach, we introduced a third GCP project specifically for running heavy jobs. Our reasoning was straightforward:
- Isolated reservation scaling: Heavy, long-running queries could now leverage more aggressive autoscaling without interfering with lighter tasks.
- Flexible configurations: We could keep reservations smaller for the “regular” jobs project, where tasks are lighter and more consistent while retaining enough headroom in the “heavy jobs” project for large-scale processing.
With this setup, we effectively prevented resource contention, ensuring that critical but smaller jobs never got delayed by outsized query-hogging slots.
By the end of our migration, we had three distinct projects:
- BigQuery admin project for managing reservations.
- Jobs project for running small to medium-sized jobs utilizing small autoscale capacity.
- Heavy jobs project for running heavy, long jobs utilizing high autoscale capacity
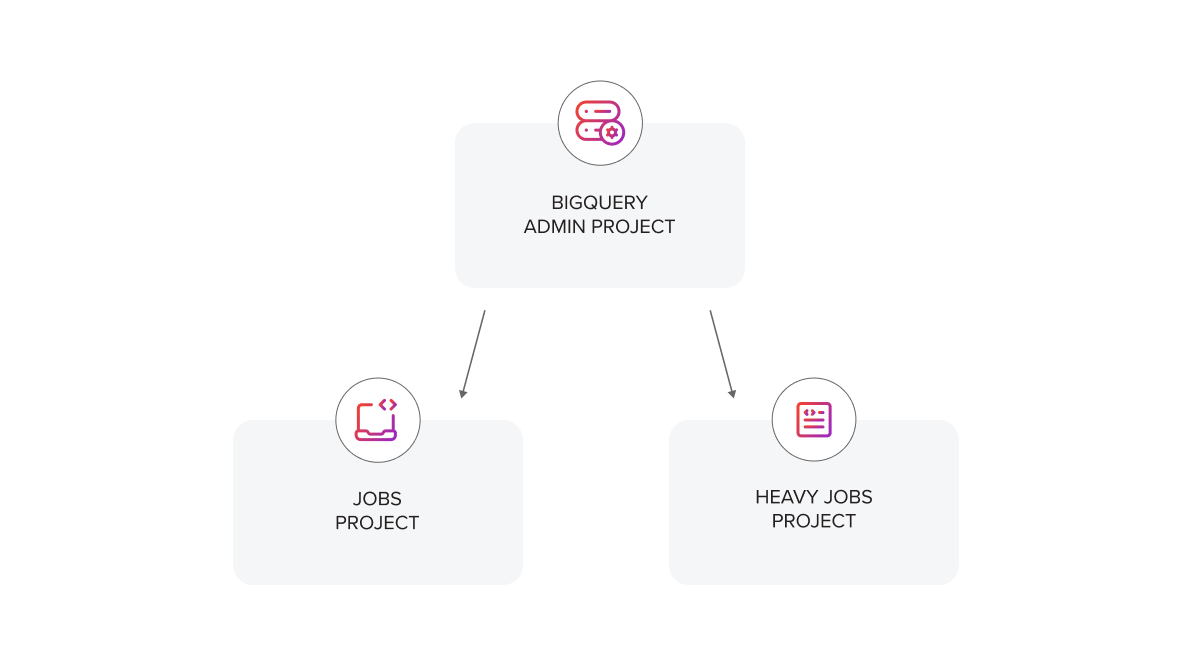
With the administrative framework in place and capacity-based pricing fully rolled out, we now have a robust foundation for continual tuning. As our data volumes and workloads evolve, we can adjust reservations or reassign jobs between projects. By following GCP’s best practices for project organization and autoscaling, we’re confident our solution will remain both cost-efficient and high-performing in the long run.
Results and impact
One of the most immediate changes after moving to capacity-based pricing was notable cost savings. Freed from the linear scaling of on-demand billing, we consistently reduced our monthly BigQuery spend by 30–40%, giving us clearer budget forecasts and easing concerns about rapidly growing data volumes.
Performance also improved, especially for batch processing, which was no longer constrained by the 2,000-slot ceiling. By isolating the heaviest data transformations in a dedicated reservation, live queries were no longer slowed down or delayed during peak workloads. This shift allowed client-facing dashboards and user interactions to remain responsive even when large-scale computations were running simultaneously.
Looking ahead, the new setup provides flexibility and readiness for future growth. We can easily adjust reservations or add capacity as our data demands evolve, ensuring that both performance and costs remain predictable. By eliminating slot contention, trimming expenses, and keeping real-time analytics fast, we’ve built a solid foundation for scaling our data operations in the years to come.
Lessons learned and best practices
Switching from on-demand to capacity-based pricing in BigQuery may seem straightforward on paper, but the reality depends heavily on your specific workloads and data usage patterns. Below are the key insights and practices we’ve gathered from our own migration journey.
Know your workload and usage patterns
A thorough analysis of concurrency, job runtimes, and data volume is essential. Spiky workloads (such as large batch jobs) often benefit from an autoscaling model, while more predictable, evenly distributed queries may justify a baseline commitment. If you only need to bypass the default 2,000-slot limit, you can also split your workloads into multiple projects while still using on-demand. This alone can alleviate slot contention without migrating to capacity-based pricing. On-demand still makes sense for low-volume or real-time queries where you need immediate slot availability. Waiting a few seconds for autoscaling to kick in could be unacceptable for certain interactive or time-sensitive workloads.
Understand BigQuery’s scaling behavior
Expect a short delay (5–10 seconds) when scaling up, and up to a minute when scaling down. Overprovisioning is also possible—BigQuery may allocate more slots than actually required. Start with a generous buffer to maintain performance, then trim down slot commitments once you have real-world data on query durations and concurrency.
Handle long-running queries separately
If you reduce your capacity too much, large or complex queries might balloon in runtime or even hit timeouts. Consider assigning them to a separate reservation or GCP project. This approach prevents lengthy jobs from blocking shorter tasks and keeps your costs predictable across different workloads.
Use built-in tools wisely
The default BigQuery slot estimator may overstate your needs, especially for spiky usage. Combining logs, dashboards, and cost reports offers deeper insights. Take an iterative approach: adjust your reservations as you learn more, rather than relying on a single tool’s guidance.
Don’t Overthink the Migration
Capacity-based pricing can be tested with minimal disruption. Come up with reasonable estimates for baseline and autoscaling, deploy, then monitor and refine. Because BigQuery migrations typically don’t involve downtime, you can make incremental changes as you gather performance and cost data.
Conclusion
Migrating to capacity-based BigQuery pricing gave us predictable costs, eliminated slot-limit issues, and improved query performance, especially for data-heavy, spiky workloads. By running careful feasibility studies, piloting with batch jobs, and continuously tuning our reservations, we achieved 30–40% cost savings and smoother operations overall. While every environment is unique, our journey shows that with the right analysis and incremental approach, capacity-based pricing can be a powerful tool for scaling data pipelines effectively.
References
- BigQuery pricing models
- Understand BigQuery slots
- BigQuery monitoring metrics
- BigQuery audit logs introduction
- Work with BigQuery reservations
- BigQuery resource usage monitoring