Last Updated on: 9th June 2025, 02:14 pm
The core component of the RTB House platform is the bidding service, responsible for processing all bid requests. A bid request is an inquiry containing details about an ad display opportunity and the target audience. Responses to these requests, specifying the bid amount for the placement, must be generated within stringent time constraints to participate in real-time bidding auctions. The platform handles approximately 25M requests per second, with response latencies measured in milliseconds. Because of this it is imperative that the architecture be extremely optimized and scalable. To achieve these latency requirements, critical bidding resources are maintained in the bidding service’s memory. While this approach minimizes latency, the incremental addition of features and resources increases memory usage, meaning that this approach is not infinitely scalable. The three most memory-intensive services were:
- Geo-IP database—a module that enriches data with geographical information such as country and city, and resolves geolocation based on IP addresses.
- User agent parsing module—a module that parses user agent strings from clients to extract relevant information. Due to the resource-intensive nature of parsing, a large cache is employed to enhance performance.
- URL context providing module—a module that provides semantic information about web page content accessible via a given URL, which is used by the bidding logic to improve placement context understanding. This module requires significant memory for internal caches and indexes.
Migration to microservices
Prior to the migration, the aforementioned services were integrated within the bidding service runtime and invoked during various phases of bid request processing. We decided to extract them as three independent runtimes, accessible via the gRPC protocol. To minimize latency, these services needed to be invoked concurrently during the same phase of bid request processing.
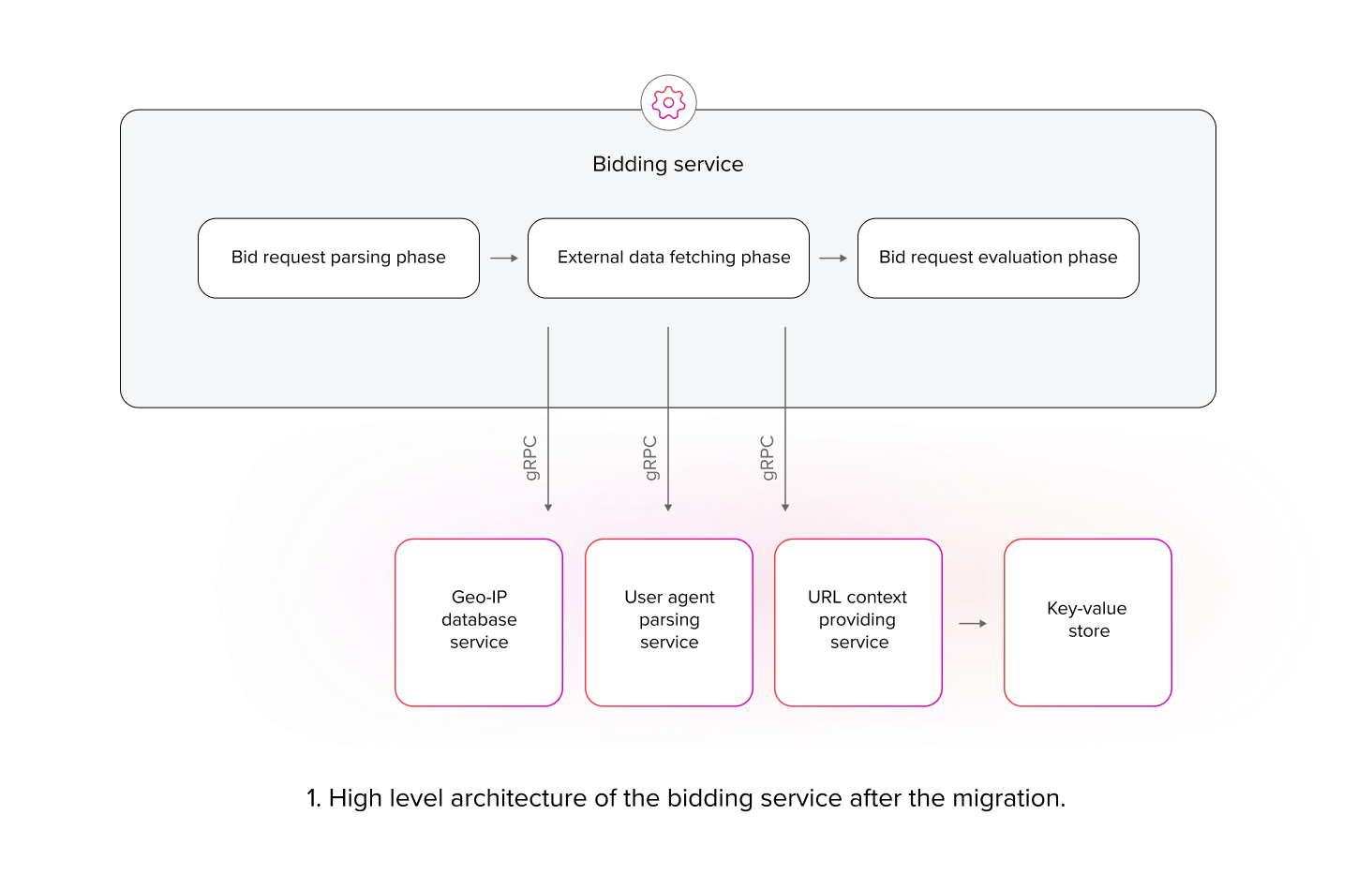
After establishing the high-level design, we shifted focus to selecting suitable technologies, techniques, and a low level architecture for implementation. Rigorous latency requirements dictated that the bid request processing duration could not be extended by more than 7 milliseconds to avoid performance degradation due to occasional timeouts. Given that each bid request processed by the bidding service would employ all three services, we estimated that the infrastructure should scale up to approximately 75M requests per second globally.
Encountered challenges
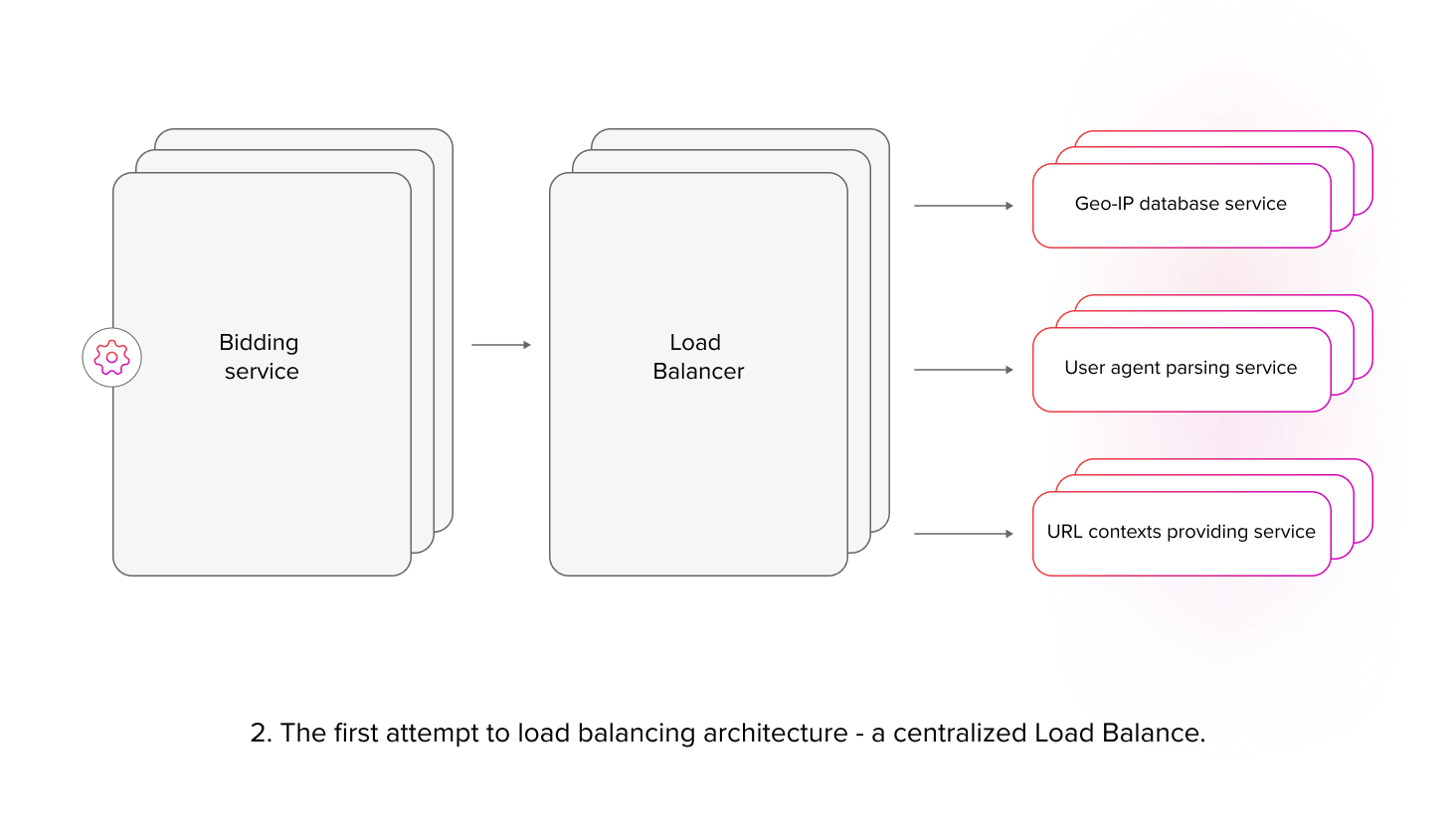
Load balancing at scale
Initially, we opted for deploying a centralized load balancer between the microservices and the bidding service as our load balancing strategy. We had used a similar approach successfully with other deployments within system components. However, the initial testing phase revealed a stark reality: to effectively handle the projected traffic volume, we would need to deploy over 100 load balancer instances across our global infrastructure. This scaling requirement arises from the nature of centralized load balancers, where handling a large number of small requests is almost as resource-intensive as handling the same amount of large ones. Consequently, this solution proved inefficient in handling the large volume of small requests and forced us to re-evaluate our load balancing approach.
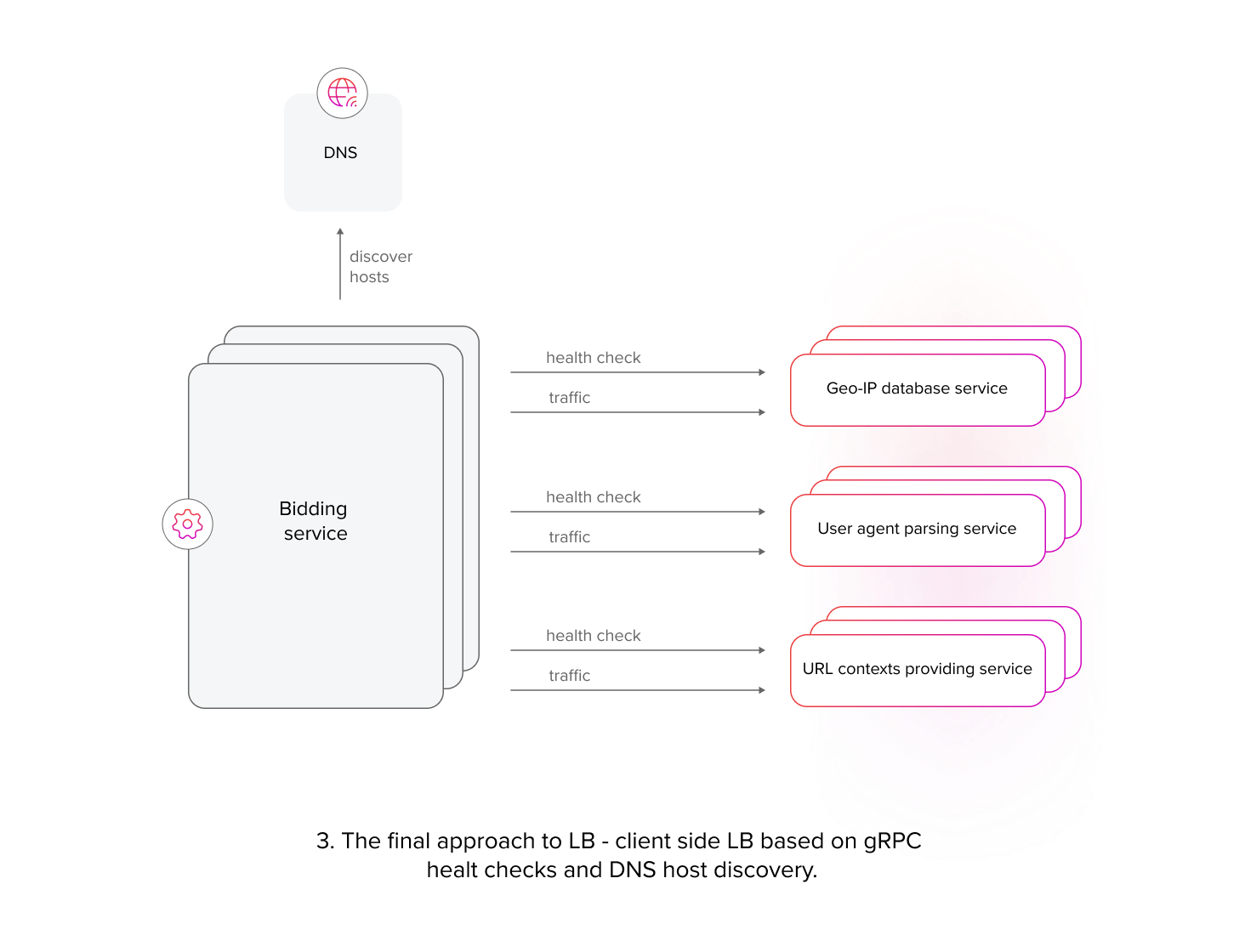
To address the limitations of the centralized load balancer model, we decided to implement client-side load balancing using built-in gRPC features [1]. In order to avoid employing complex load balancing algorithms, we ensured that each service instance was deployed on identical compute resources. Given this uniformity, we were able to apply a straightforward round-robin algorithm for traffic distribution, along with DNS-based service discovery. We also utilized the native gRPC health checking protocol [2]. This approach, although it has some limitations that we probably will have to address in the future, yielded substantial resource savings and provided us with a simple and rapid implementation path.
Overhead of sending small messages
Having successfully optimized the load balancing architecture, we encountered a subsequent performance challenge stemming from the sheer volume of small requests directed at our microservices. Due to the lightweight nature of the business logic within each service, we observed a substantial overhead within the network and service binding layers. Our analysis revealed an inefficiency: in the case of the Geo-IP database service, a mere 20% of compute resources were allocated to the business logic. The remaining was consumed by overhead processes such as HTTP/2 request handling and thread pool dispatching. This situation presented a significant concern, as it would require from us substantial additional hardware to accommodate the load. We were thus forced to come up with a strategy to mitigate this resource utilization bottleneck.
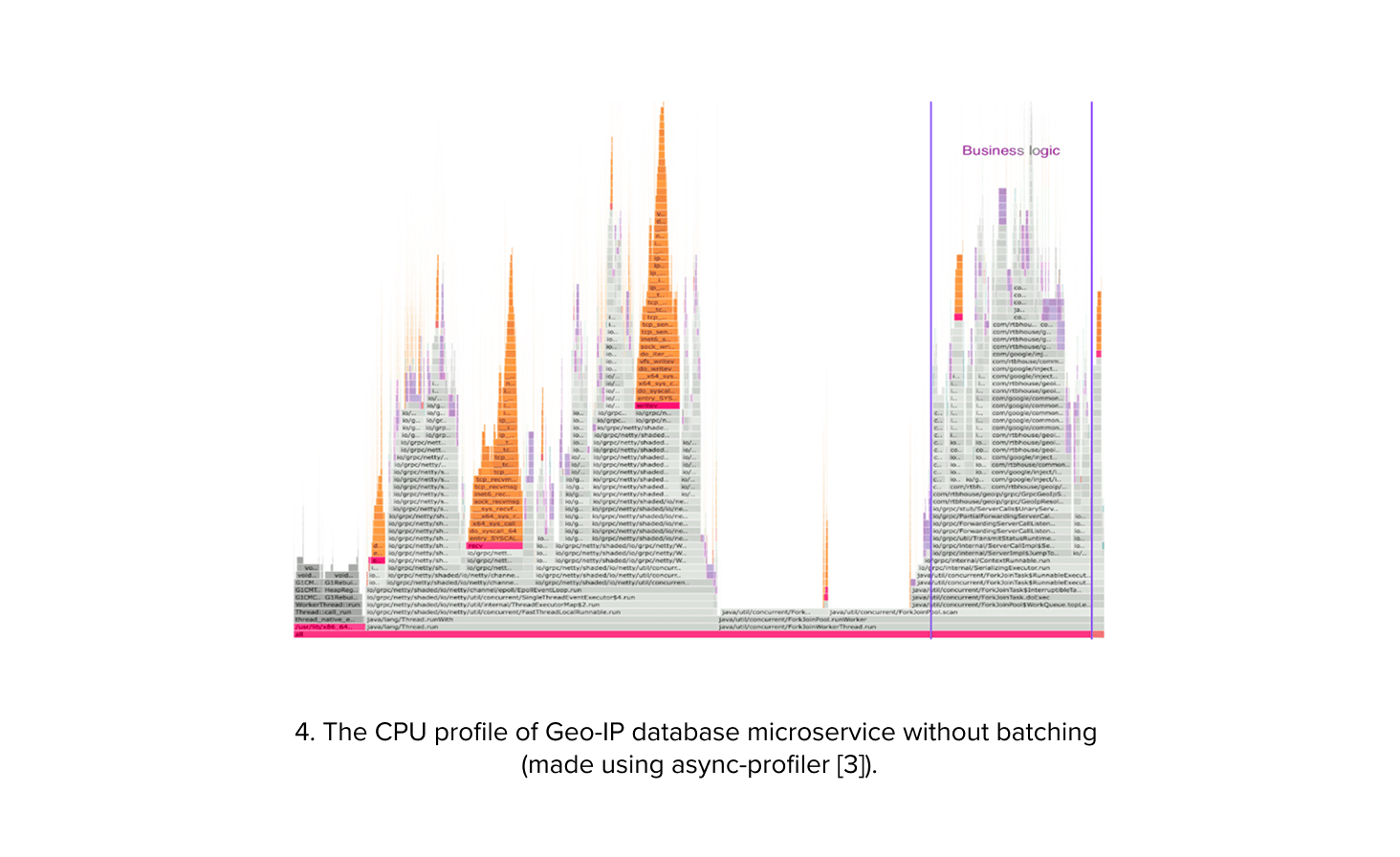
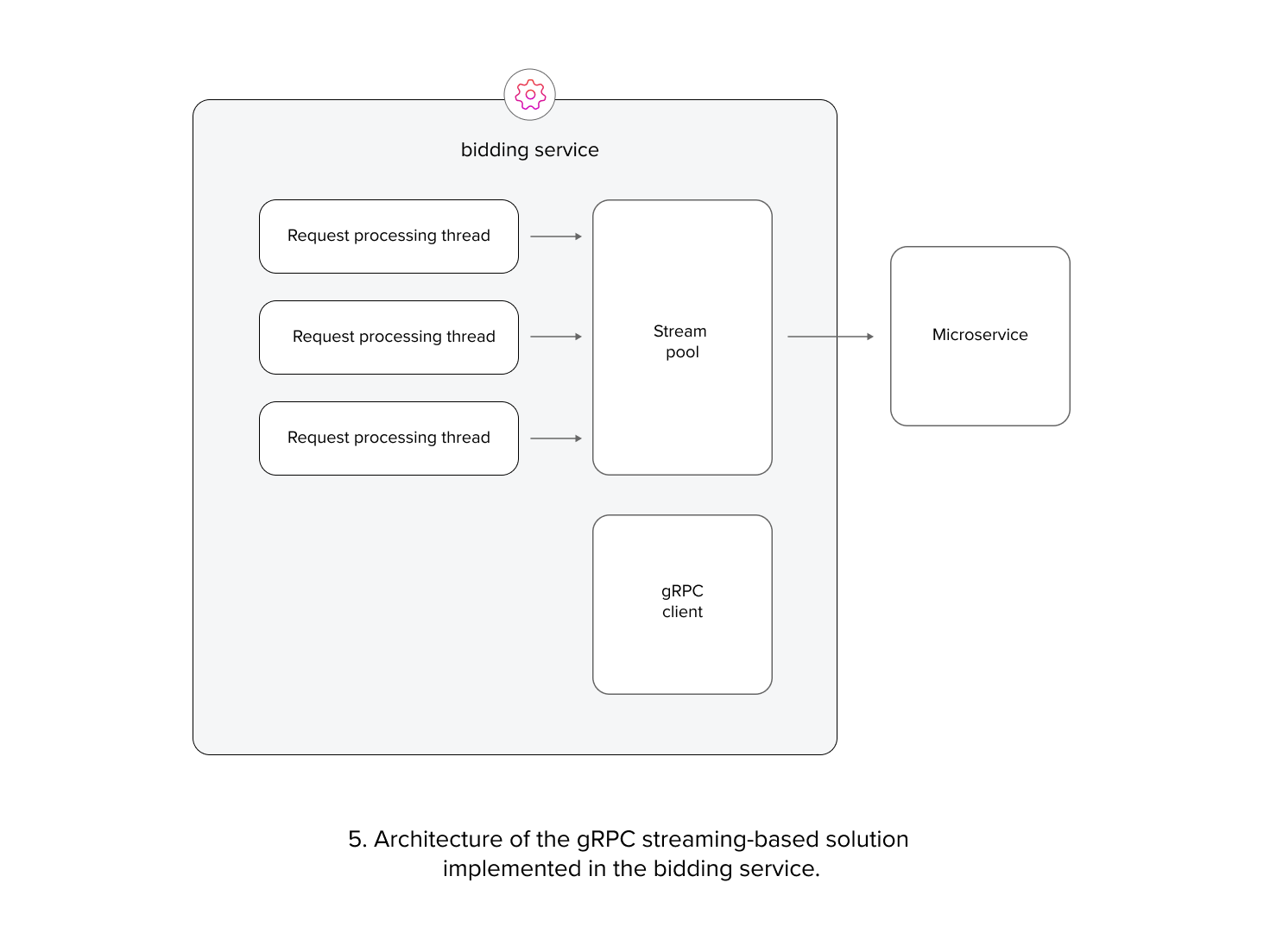
Initially, to address the performance bottleneck, we attempted to replace unary gRPC calls with streaming calls. This involved establishing a pool of persistent streaming connections from each bidding service instance to the microservices, and using these connections as a transport layer for requests. Reusing persistent streams was aimed at reducing the overhead of sending headers, processing load balancing decisions, and minimizing resource consumption on the microservice side. However, this approach introduced complexities in managing the stream pool. Additionally, it only improved microservice performance by approximately 50% (measured by request volume per instance with fixed hardware). This solution did not resolve the thread pool dispatching overhead and was still impacted by inefficient TCP frame packing.
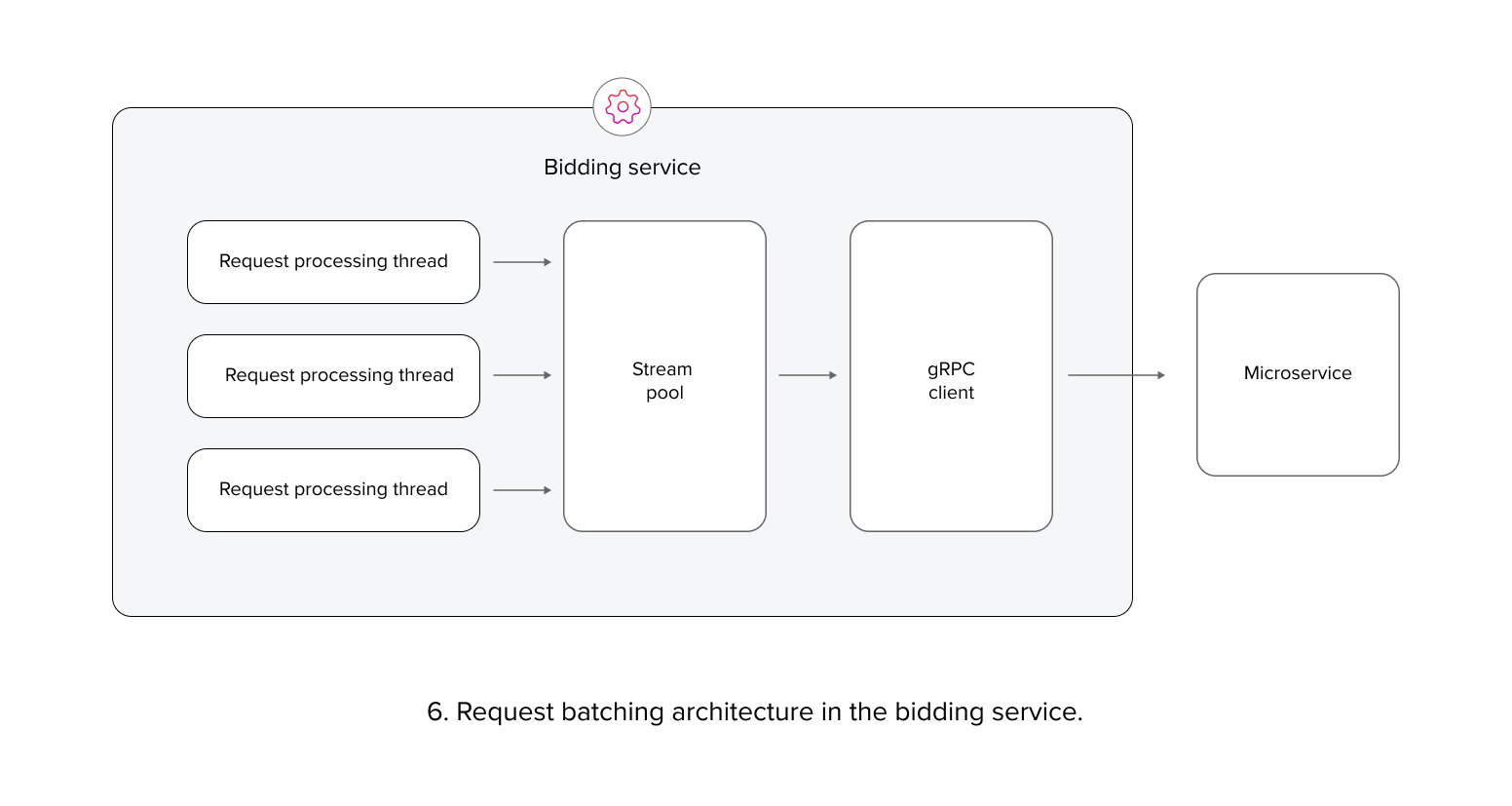
Building upon these observations, our second approach involved implementing and testing a batching mechanism. Each bidding service instance was equipped with a batching buffer to aggregate requests before transmitting them to the microservices. This resulted in fewer, but larger, requests at the network and microservice binding layer. We found that increasing the batch size improved performance, but also increased request latency. Ultimately, a batch size of 10 was determined to be an optimal balance. This strategy increased microservice performance by 150%, albeit with an increase in request latency.
Low latency & garbage collection
As previously mentioned, while the batching mechanism improved overall performance, it also increased latency. Although the average request time was approximately 2.5 milliseconds, well within the 7 ms limit, we encountered an issue with the 98th and 99th percentiles of microservice request times i.e. tail latency. These percentiles exceeded the limit, potentially leading to timeouts for some requests processed by the bidding service. All services were implemented in Java, and JVM performance is known to be significantly affected by garbage collection. Initially, we employed the G1 garbage collector based on prior experience. However, we observed that the high volume of small requests placed considerable pressure on the garbage collector, resulting in frequent G1 pauses that substantially increased the duration of certain requests. Attempts to mitigate this through G1 parameter tuning proved unsuccessful.
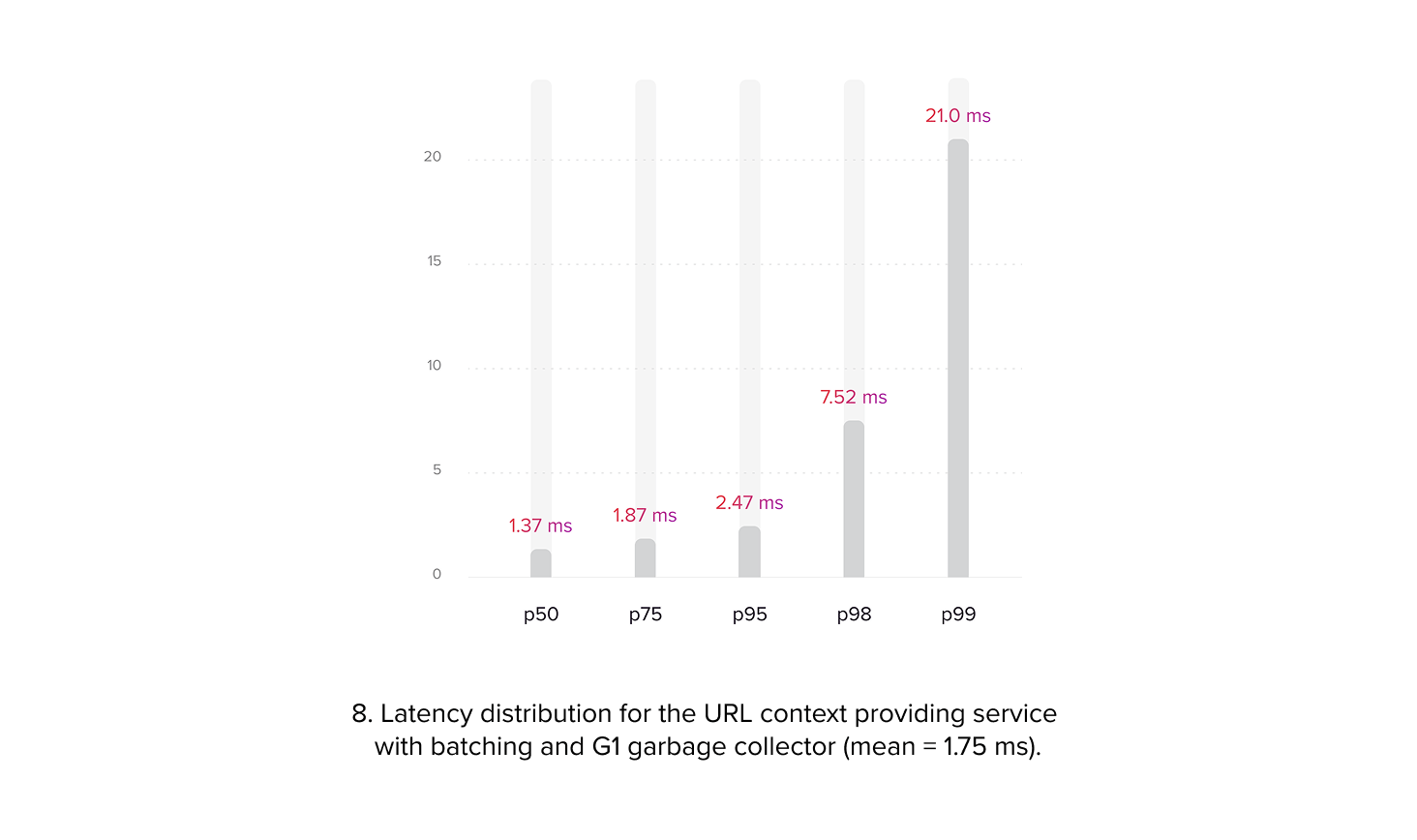
To address the high latency observed in a subset of requests, we switched to the ZGC, which is designed for applications with strict latency requirements. Unlike G1, ZGC performs most of its work concurrently with application threads, resulting in fewer and shorter ‘stop the world’ pauses. However, ZGC can have a higher memory overhead compared to G1, requiring more resources. The choice between these two garbage collectors involved a trade-off between latency and memory consumption. While some reports suggest ZGC is less CPU efficient, we did not observe any noticeable trends indicating this in our testing [4-6]. Ultimately, we implemented generational ZGC with a dynamic number of GC threads, as this configuration allowed us to fix the tail latency problem while maintaining acceptable resource consumption.
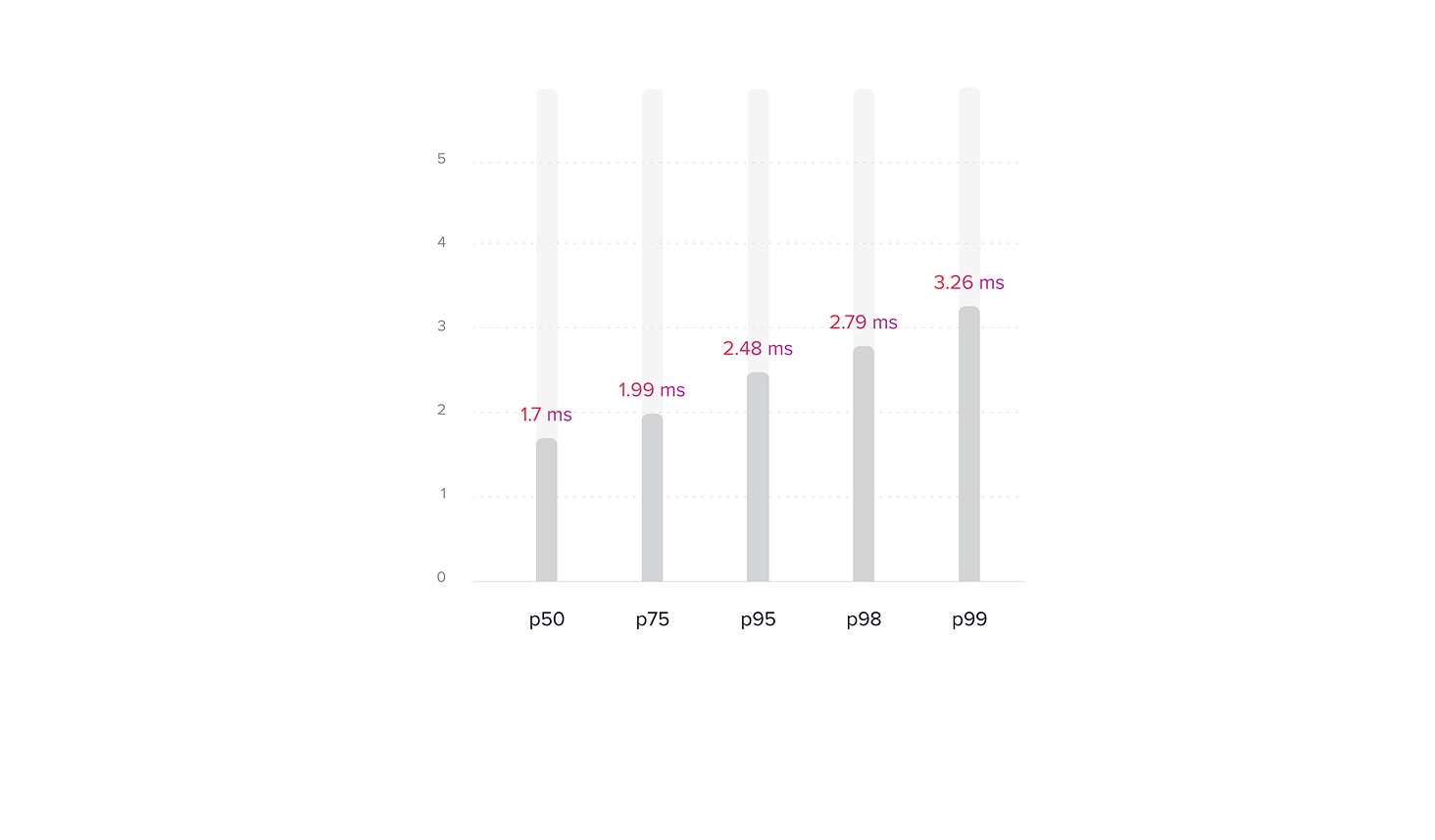
Resiliency
Our final challenge was ensuring the solution’s overall resilience. We observed occasional timeouts and errors from the microservices, particularly with the URL context providing service due to its connection to an external key-value store. This issue was exacerbated by the introduction of batching, as larger requests meant a single problematic record could affect an entire batch. Additionally, unexpected microservice instance failures without graceful shutdowns also contributed to these issues. To address this, we implemented the hedging technique, a feature provided by the Java gRPC client. Hedging was configured to trigger a new request attempt if no response was received within a specific timeframe or a retryable error occurred. This differs from a simple retry policy as it initiates new attempts even without an initial response. However, hedging requires careful management to prevent system overload from excessive attempts during incidents. To mitigate this risk, we applied a hedging throttling policy from the Java gRPC library [7].
Final architecture
The final architecture of the our solution looks like this:
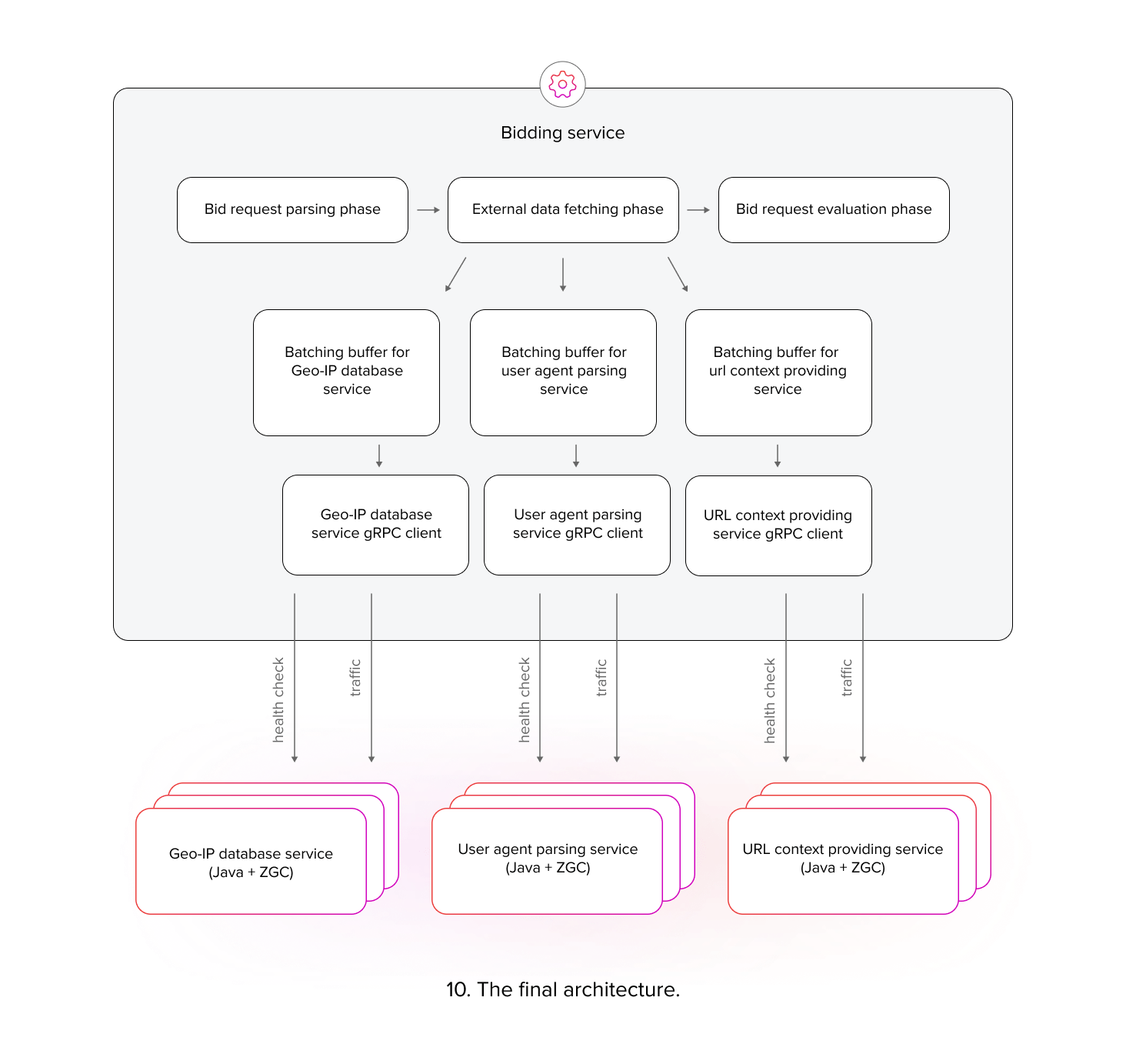
The migration to microservices was successfully completed, resulting in the extraction of these services from the bidding service monolith and the optimization of both resource utilization and request latency. We also managed to ensure the resilience of the solution.
Reference
- https://grpc.io/docs/guides/custom-load-balancing/
- https://grpc.io/docs/guides/health-checking/
- https://github.com/async-profiler/async-profiler
- https://docs.oracle.com/en/java/javase/22/gctuning/garbage-first-g1-garbage-collector1.html
- https://docs.oracle.com/en/java/javase/22/gctuning/z-garbage-collector.html
- https://www.linkedin.com/pulse/jdk-17-g1gc-vs-zgc-usage-core-exchange-application-performance-raza
- https://grpc.io/docs/guides/request-hedging/