Last Updated on: 17th June 2024, 04:01 pm
Exploring recent advancements in leveraging LLMs for recommendation systems.
In the past few years, Large Language Models (LLMs) have witnessed a remarkable increase in popularity, finding diverse applications across various domains, particularly within natural language processing and computer vision. This burgeoning interest prompts us to ask the following question: how can LLMs be effectively integrated into recommendation systems? Whether serving as feature encoders within traditional recommendation pipelines or operating as self-sufficient, end-to-end recommendation mechanisms, LLMs hold the potential to impact the landscape of personalized suggestions. But what does the process of incorporating these models entail?
This blog post aims to explore the recent advancements in leveraging LLMs for recommendation systems, providing an overview of recent developments and methodologies.
Recommendation systems model architectures
The evolution of recommender systems has seen a shift from early, simple techniques, such as factorization machines for CTR prediction or collaborative filtering for product recommendation, to more sophisticated Deep Learning approaches, such as deep & cross networks, two-tower models, and many others. Can the next wave, consisting of transformers and LLMs, be employed in the recommendation space?
 Evolution of recommendation systems model architectures
Evolution of recommendation systems model architectures
Recommendation systems pipeline
Typically, a recommender system follows a multi-stage process: initially, a broad set of potential items is narrowed down using simpler models or rule-based filters. This step significantly reduces the pool of candidates to a manageable size, upon which more complex models can be applied for the final selection of recommendations. However, the introduction of LLMs presents a transformative approach. LLMs have the capacity to bypass the traditional multi-tiered filtering and ranking process by directly generating recommendations from the entire pool of items. This capability allows for considering the full spectrum of options in one step, potentially streamlining the recommendation process and enhancing the relevance of the output.
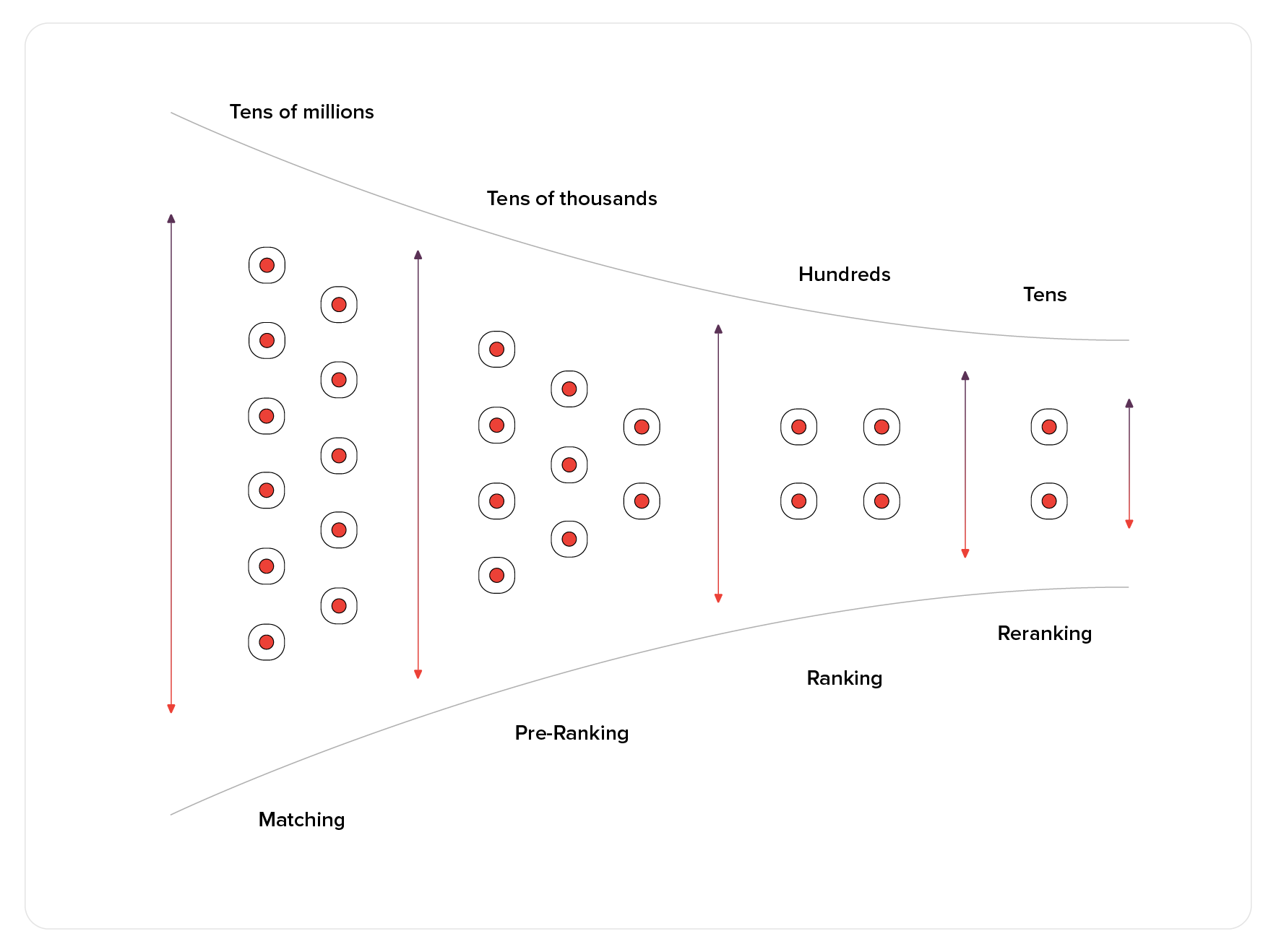 Ranking stages of traditional recommendation pipeline. Image source: https://arxiv.org/abs/2006.09684
Ranking stages of traditional recommendation pipeline. Image source: https://arxiv.org/abs/2006.09684
Item recommendation generation
Incorporating item and user information can be achieved through various methods: embedding the data within the pre-training phase, linking to an external database in a Retrieval-Augmented Generation (RAG)-like manner, or including it directly in the prompt for smaller datasets.
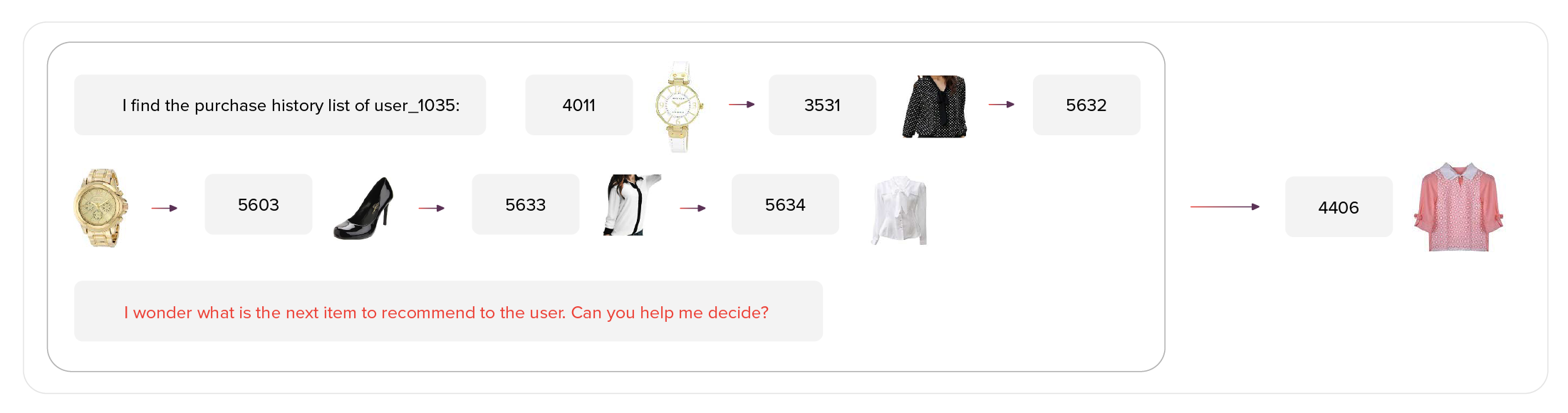
But what should an LLM output when recommending an item? Given its language interface, it can output the description of an item, query to the item’s database, embed what will be used to semantically search over item space, or just the item ID itself. Much of the current research on LLMs for recommendation focuses on the latter, generating the item ID directly.
When dealing with large amounts of possible items, assigning each item a separate token value would be infeasible computationally. Given that the item ID can span as multiple tokens, we can easily represent large item spaces using short token sequences. During autoregressive generation, we can modify the search algorithm to only take into account the existing items and thus prevent item ID hallucinations.
Addressing the construction of item ID sequence structure in a way that avoids spurious correlations presents an intriguing challenge. Simple numerical sequencing or just item titles might induce unintended associations. Alternatives like hierarchical indexing, based on user-item interactions or semantic attributes, offer a more nuanced approach to categorizing items, potentially enhancing the relevance and precision of recommendations.
 Visualisation of item ID generation. Image source: https://llmrecsys.github.io/
Visualisation of item ID generation. Image source: https://llmrecsys.github.io/
Handling different recommendation tasks
The advantage of using natural language as the interface for recommendation systems is clear: it allows for a flexible and unified approach to various types of recommendation tasks. Whether it’s predicting ratings, generating top-n item lists, providing sequential recommendations, offering explanations for recommendations, summarising reviews, or facilitating conversational recommendations, the same setup can address these diverse needs effectively. Additionally, the extensive general knowledge embedded in these models through the pre-training phase can be leveraged to enhance the recommendations even further.
 LLMs using language interface can solve many different recommendation tasks using the same setup. Image source: https://arxiv.org/abs/2307.02046
LLMs using language interface can solve many different recommendation tasks using the same setup. Image source: https://arxiv.org/abs/2307.02046
Multimodality
Integrating multiple types of data, such as images or videos, into recommendation systems using LLMs is not only possible but increasingly beneficial. By equipping LLMs with encoders that translate these diverse data formats into a common token space, we can significantly enhance the system’s understanding and responsiveness to user preferences. Empirical evidence suggests that incorporating such multimodal training can further improve the performance of recommendation systems, making the recommendations more accurate and relevant to users.
 One can easily adjust an LLM pipeline to work with images when generating recommendations. Image source: https://arxiv.org/abs/2305.14302
One can easily adjust an LLM pipeline to work with images when generating recommendations. Image source: https://arxiv.org/abs/2305.14302
Zero-shot recommendation performance
How effective are pre-trained LLMs at handling recommendation tasks without any task-specific fine-tuning, known as zero-shot inference? Given their extensive pre-training on vast datasets, one might expect them to achieve noteworthy results even in unfamiliar tasks. However, when evaluated using standard automated metrics, their performance typically falls short of models that have been fine-tuned on specific recommendation tasks. Interestingly, this changes when the quality of recommendations is assessed based on human preferences. In such cases, LLMs often excel, likely benefiting from techniques like Reinforcement Learning from Human Feedback (RLHF) or Direct Preference Optimization (DPO), which fine-tune the models to align more closely with human judgment.
One can try to apply LLM for recommendation in a zero-shot manner. Image source: https://arxiv.org/abs/2304.10149
Other use-cases
Beyond acting as independent recommendation engines, Large Language Models (LLMs) can be applied in several innovative ways within the realm of recommendation systems:
- As Feature Encoders: LLMs can transform raw data into meaningful items or user features that can be used in the standard recommendation pipeline.
- As Scoring/Ranking Functions: They can evaluate and prioritize recommendations, ensuring that the most relevant items are presented to the user.
- As Conversational Recommenders: By facilitating natural language interactions, LLMs can guide users to discover products or content through conversational interfaces.
- As Pipeline Controllers: LLMs can oversee and optimize the sequence of operations in recommendation pipelines, addressing various tasks efficiently.
These diverse applications showcase the adaptability of LLMs, making them promising assets across the spectrum of recommendation system design and implementation.
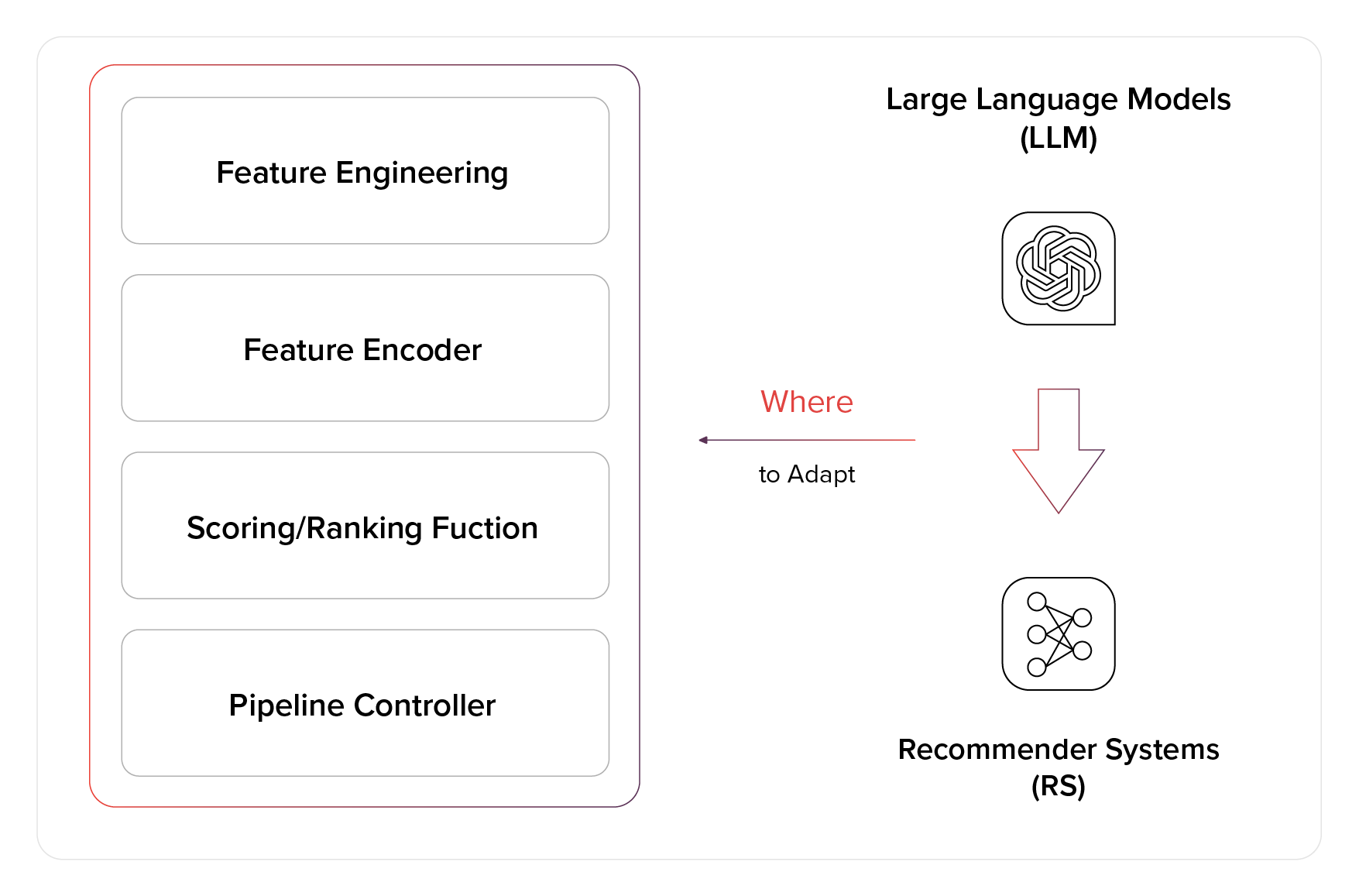 LLM can also be used alongside the recommendation system pipeline as a feature encoder, scoring/ranking function, conversational recommender, or pipeline controller. Image source: https://arxiv.org/abs/2306.05817
LLM can also be used alongside the recommendation system pipeline as a feature encoder, scoring/ranking function, conversational recommender, or pipeline controller. Image source: https://arxiv.org/abs/2306.05817
Summary
The exploration of LLMs within the recommendation domain is both fascinating and evolving rapidly. These models bring a dynamic edge to the traditional landscape of recommendation systems, offering new methodologies and insights that were previously unattainable.
At RTB House, despite the fact that we still leverage conventional pipelines and Deep Learning models, we have begun to see promising integrations of LLMs into our system. An example of such an endeavor is ContentGPT, which illustrates the potential of LLMs to enhance our recommendation capabilities.
Acknowledgement
This blog post is based on more detailed survey papers on the area: Large Language Models for Generative Recommendation: A Survey and Visionary Discussions by Lei Li et al., Recommender Systems in the Era of Large Language Models (LLMs) by Wenqi Fan, et al., along with RecSys 2023 tutorial on LLMs in recommendation by Wenyue Hua, et al., which I attended as the RTB House representative. I am thankful for the opportunity to learn and share this blogpost with the community.
References
- Large Language Models for Generative Recommendation: A Survey and Visionary Discussions
- Recommender Systems in the Era of Large Language Models (LLMs)
- A Survey on Large Language Models for Recommendation
- How Can Recommender Systems Benefit from Large Language Models: A Survey
- RecSys 2023 Tutorial: Large Language Models for Recommendation
- Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)