Last Updated on: 13th June 2024, 08:13 pm
Architecture & lessons learned.
In the previous post we presented our real-time data processing infrastructure at RTB House. This time we would like to explain how we managed to scale it 10x, to provide full multi-dc architecture and data synchronization but also to improve and rewrite all our processing components. Additionally we would like to present our Kafka’s client library which we decided to open-source and which gives some features we really needed.
The fourth iteration: multi-dc
New requirements
First of all, we were growing and we were increasing volume of our data extremely fast. When we published our first post on this topic one year and a half ago, we were processing up to 350K bid requests per second at that time, now it is almost 3.5M per second which means that also our processing infrastructure needed some scaling. Currently it processes up to 250K events per second in 4 data-centers which gives 50TB of processed data every day. There are some numbers which describe the scale of our processing infrastructure:
- 26 Kafka brokers (85 topics, 5000+ partitions) in 6 clusters
- 44 Docker engines, 800+ Docker containers (processing components only)
- 2PB+ data (up to 10GB/s) on HDFS
- 1PB+ data (up to 10GB/min) on BigQuery
- 40TB data (up to 50K events/s) on Elasticsearch
- 80TB data (up to 8K events/s) on Aerospike (processing only)
In the meantime, we added another data center, the second in the USA and we needed to provide full multi-DC support. For example, it could happen that bid requests were processed in one DC and user events came from another one which means that we needed to synchronize our user profiles between all our DCs. What is more, it could happen that an impression was sent from the West Coast and an appropriate conversion was sent from the East Coast, so we needed to merge streams of our events for related DCs.
Another decision we needed to make was connected with our message delivery semantics for all our components. Of course we wanted to have accurate data but it was good enough for us to require at-least-once output semantics for all our processing components and deduplicate events at the end.
Finally, we improved and rewrote our stats-counter using Kafka Consumer and data-flow using Kafka Streams, we replaced Solr and Flume pair by Elasticsearch and Logstash and we added components responsible for mentioned synchronization: merger, dispatcher and loader.
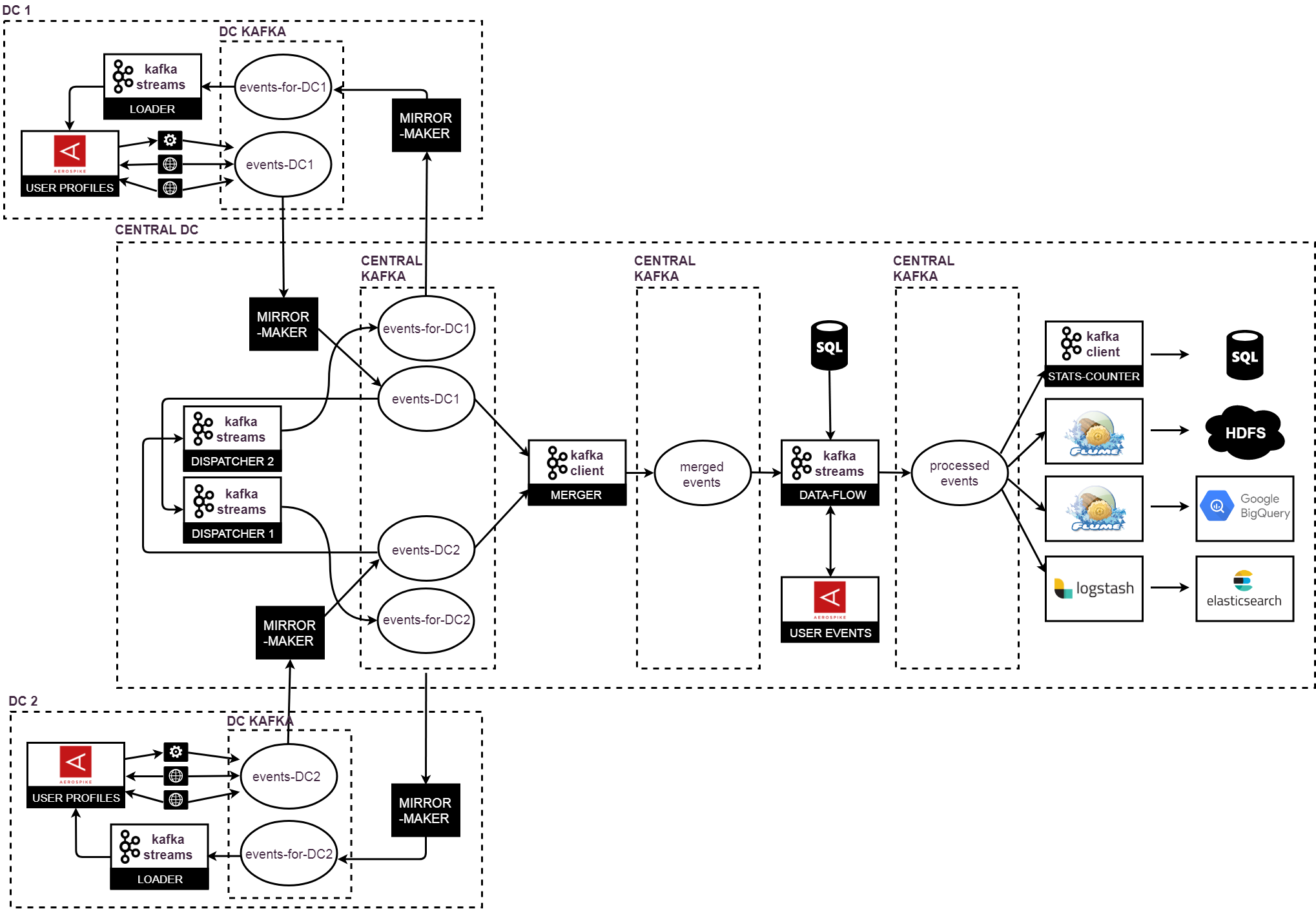
Multi-dc architecture
The diagram below shows high-level architecture of our current processing infrastructure and data synchronization. Not only are events sent from local DCs to the central one for further processing but also they are dispatched and sent back to related DCs were they are loaded to local Aerospikes and co-create local user profiles. Related streams of events are merged and ordered before processing which is done in the same way how it was before including streaming to HDFS, BigQuery, Elasticsearch and Postgres.
New data-flow on Kafka Streams
We decided to implement a new data-flow and replace the previous solution with Storm by Kafka Streams. The truth is that we found Kafka Streams very useful for the microservices in our data processing infrastructure. We like the fact that it is a simple library with no processing cluster and without external dependencies. Because of that it was much easier for us to use it in our existing Docker infrastructure. It is fully integrated with core abstractions in Kafka like its parallelism model and group membership mechanism which provides good distribution and fault-tolerance. Only one problem results from the design that tasks are assigned to partitions so this distribution is limited by partitions count. It does event-at-a-time processing which means that we do not have microbatches like it was in the case of Storm Trident. It ensures exactly-once processing (by Kafka transactions and producer’s sends and consumer’s commits which could be done atomically), even if we needed only at-least-once.
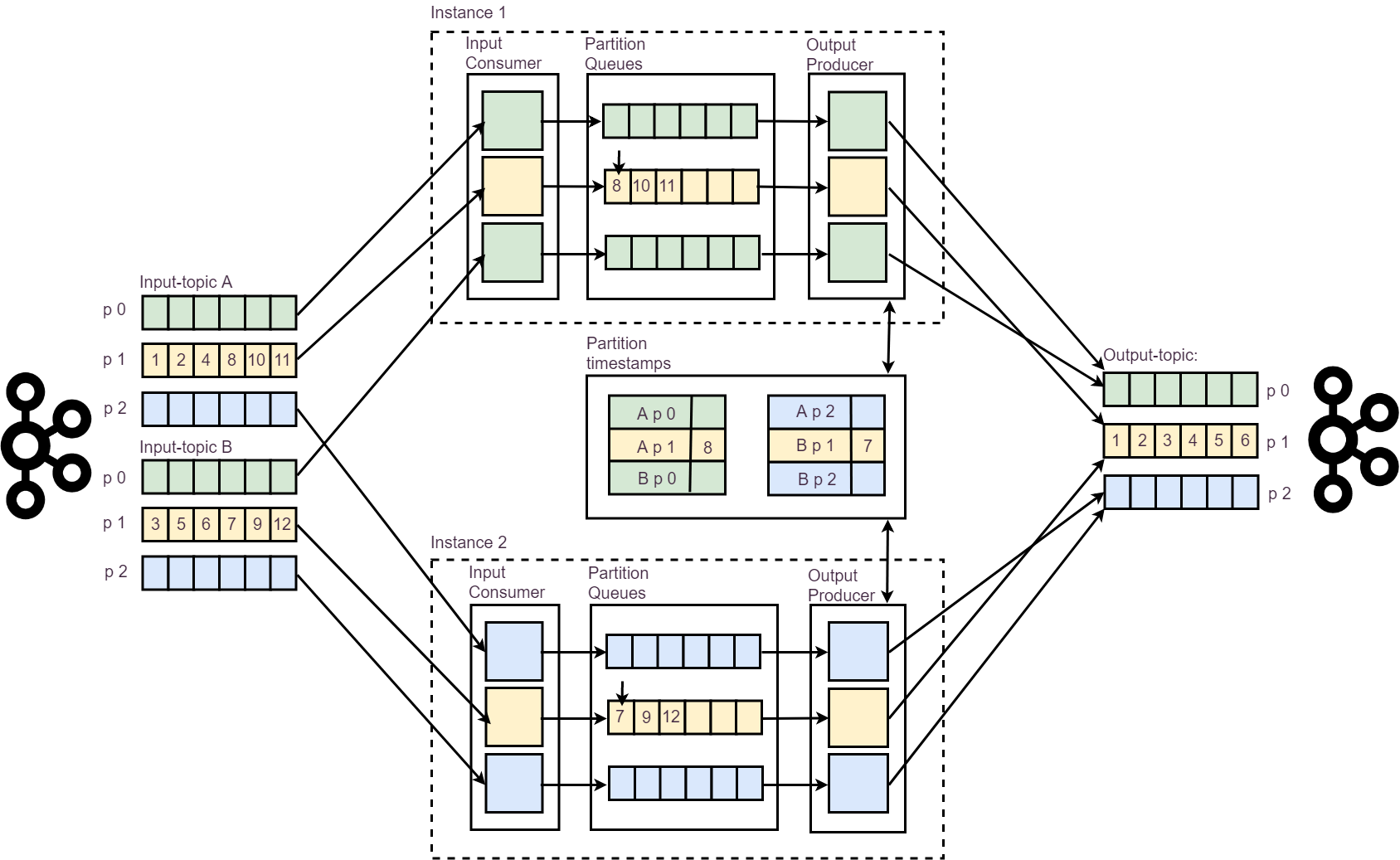
Merger on Kafka Consumer API
We based our merger component on standard Kafka Consumer API. Our partitioning is unified in all DCs and cookie to partition mapping is deterministic which means that we merge pairs of partitions from related topics. It is kind of merge-sort but in context of streams: we merge two sorted streams of events together and produce new, sorted one. We use special, technical topic for this synchronization and related partitions could be consumed and processed by two different merger instances.
The current iteration: Kafka Workers
Requirements
We would like to introduce our processing library which we have open-sourced recently: Kafka Workers. As presented, we used different technologies for different microservices including: Storm (or later Kafka Streams), pure Kafka Consumer API, Flume and Logstash. We wanted to replace this mix of technologies by a unified solution for all our use cases, especially that we felt that still a lot of them had some drawbacks.
The idea was to implement something similar to Kafka Streams that would offer some features we really needed. The first requirement was a higher level of distribution – we wanted to launch more tasks and threads than it was limited by partitions count. The second requirement was a possibility to pause and resume processing for a given partition and it was necessary for our merger. Additionally we wanted to allow asynchronous processing but it meant that we needed tighter control of offsets commits and backpressure mechanism. We wanted to provide processing timeouts and handling all possible exceptions. Finally, at-least-once semantics was good enough for us.
Currently we work on multiple consumers which means that in the future there will be an option to configure a few different consumers separately. So far we have adopted Kafka Workers to our merger and data-flow successfully but currently we are working on BigQuery, HDFS and Elasticsearch streaming.
Internals
To use Kafka Workers user should implement two interfaces: WorkerPartitioner and WorkerTask. User-defined WorkerPartitioner is used for additional sub-partitioning which could give better distribution of processing. It means that stream of records from one TopicPartition could be reordered during processing but records with the same WorkerSubpartition remain ordered to each other. It leads also to a bit more complex offsets committing policy which is provided by Kafka Workers to ensure at-least-once delivery. User-defined WorkerTask is associated with one of WorkerSubpartitions. The most crucial are: accept() and process() methods. The first one checks if a given WorkerRecord could be polled from internal WorkerSubpartition’s queue peek and passed to process method. The second one processes just polled WorkerRecord from given WorkerSubpartition’s internal queue. Processing could be done synchronously or asynchronously but in both cases one of the RecordStatusObserver’s methods onSuccess() or onFailure() has to be called. Not calling any of these methods for configurable amount of time will be timeouted.
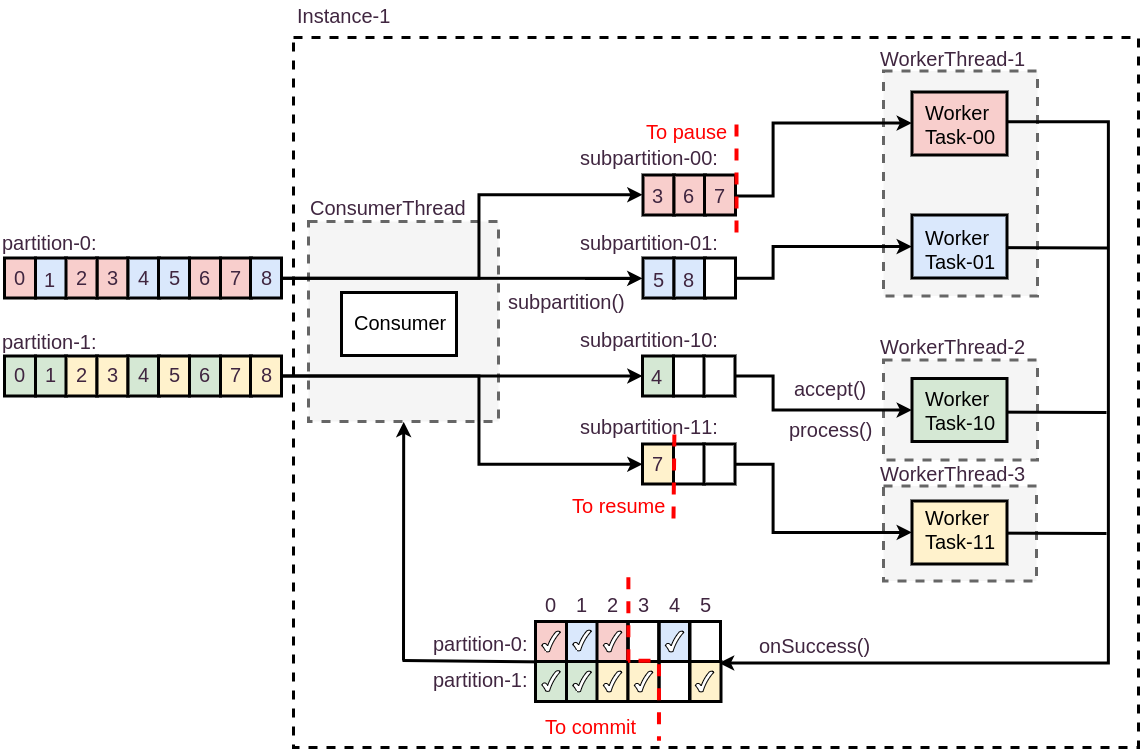
Internally one Kafka Workers instance launches one consumer thread and configurable count of worker threads. Each thread can execute one or more WorkerTasks and each WorkerTask processes WorkerRecords from internal queue associated with given WorkerSubpartition. Kafka Workers ensures by its offsets state that only continuously processed offsets are committed.
Summary
To sum up, in the first iteration we did the whole processing in the core platform by rewriting mutable impressions in Cassandra. It was quite an inflexible solution but what was even worse, we were forced to send the same data a number of times from Cassandra to HDFS. In the second iteration we added Kafka and used it for transporting our data. This time the platform was producing raw events but we had different types of information with a different delay. Still, we were forced to rewrite the same data on HDFS repeatedly. In the third iteration we did a real-time processing of immutable streams of events and we streamed the generated events to various data sources. In the fourth one we added data synchronization between data centers and we added merging streams of events for related DCs which gave us a real multi-DC architecture. In the last one we launched our own processing library and we are rewriting our processing components with it.
In conclusion, what have we achieved exactly by those improvements? As previously mentioned, new architecture fits well with processing data from various DCs and guarantees end-to-end exactly-once processing. After the third iteration, not only did we achieve the real-time processing but this time streamed events are available almost online both in HDFS and BigQuery. HDFS’s data is used mainly for our machine learning. On the other hand, we have easily accessible and queryable data on BigQuery with online view. It gives us new possibilities to monitor our platform infrastructure but also our bidding logic. We can react quickly if something is going wrong. Additionally, we are able to count new types of indicators and monitor them. The current bidding platform is completely separated from complex events processing and its business logic. Because of this separation, the core system is much more stable, but also data processing is of higher quality. It was achieved partially by the second iteration but with the last one data-flow is easier to develop, test and maintain. Additionally, events processing could be paused or even reprocessed now if it is needed. Last but not least, every service in our central data-center is dockerized so our processing components are easy to maintain and to scale horizontally. With some custom-built tools we have achieved so-called one-click deployment for our central processing infrastructure.