We have just open-sourced our kafka-workers, a library we use at RTB House for our processing components.
There are a lot of really good solutions available on the market like Kafka Streams, Flink, Storm or Spark Streaming. In particular, we found Kafka Streams very useful for the microservices in our data processing infrastructure. We like the fact that it is a lightweight library with no processing cluster and without external dependencies. It takes full advantage of Kafka’s parallelism model and group membership mechanism.
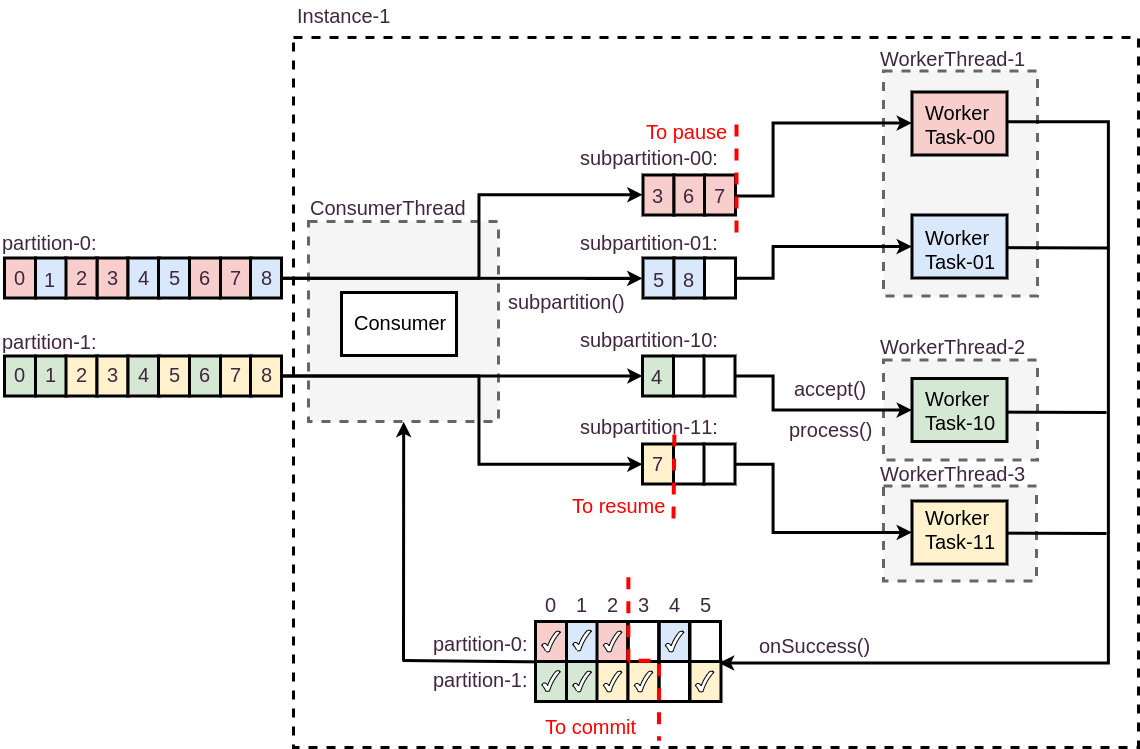
Kafka Workers does the same but implementation details are different. It could be said that Kafka Workers is something between low-level Kafka Client API and Kafka Streams, but additionally it gives some features we really needed:
- a higher level of distribution,
- tighter control of offsets commits,
- possibility to pause and resume processing for given partition,
- asynchronous processing,
- backpressure.
The diagram below shows how it works:
For more details please check out our GitHub page: README.